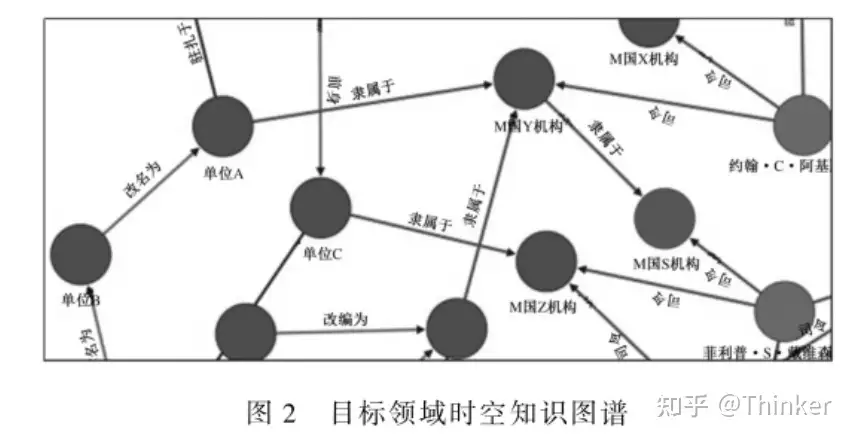
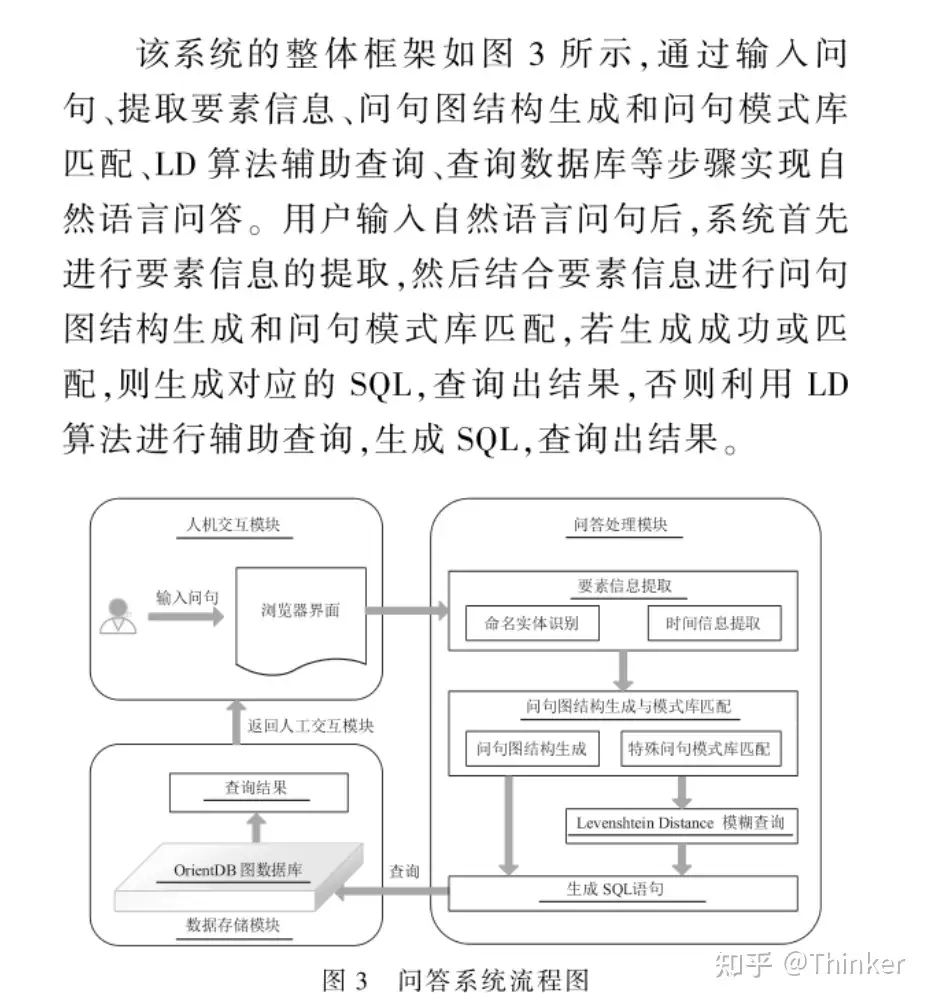
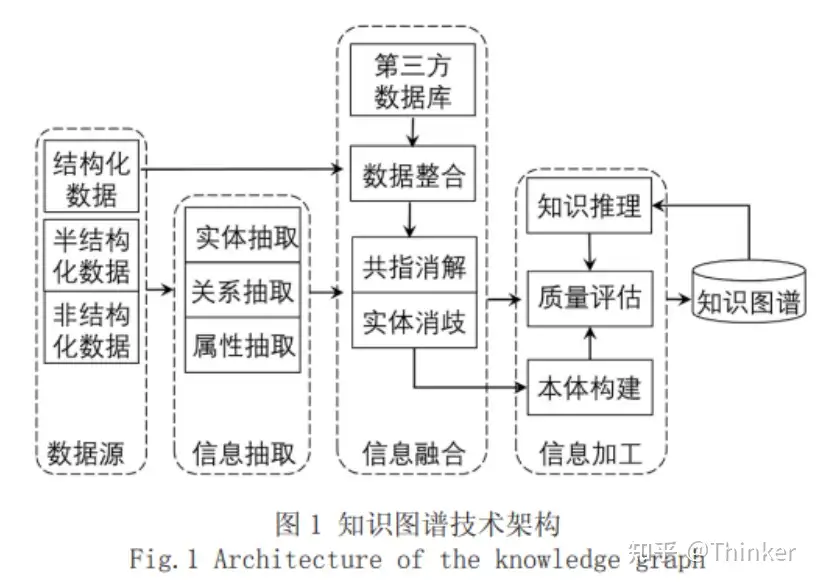
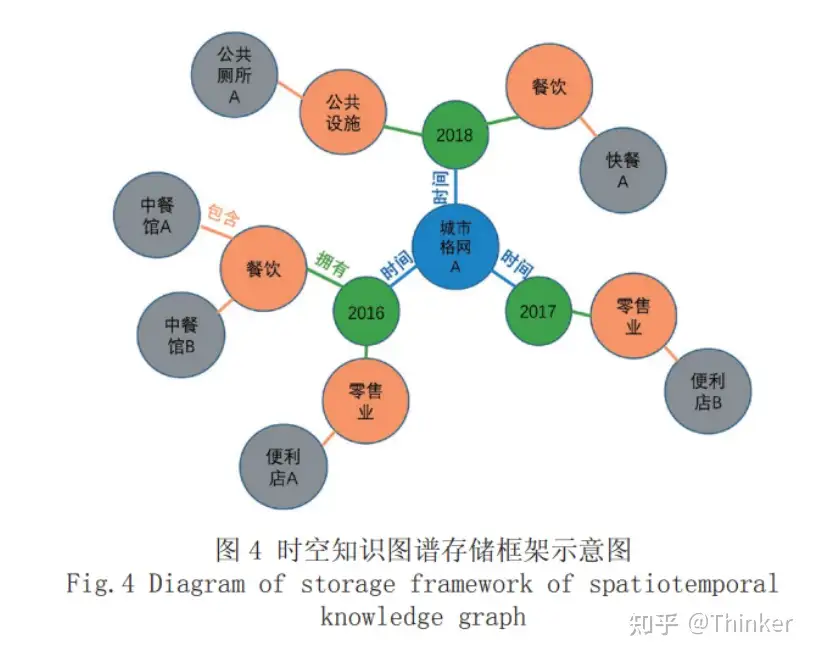
背景
概念
资产管理是一个涉及组织、协调、监督和控制企业或其他机构资产的综合性管理过程。这些资产包括流动资产(如现金、应收账款、存货)、固定资产(如建筑、机器、设备)、无形资产(如专利、商标、商誉)以及其他金融资产等。资产管理的目标是确保资产的有效利用,以支持组织的战略目标和提高财务表现。具体内容包括但不限于:
- 资产配置:决定资产的分配方式和投资方向,以实现风险和回报的最佳平衡。
- 资产使用:确保资产被有效利用,以支持日常运营和长期目标。
- 资产维护:包括资产的保养、维修和升级,以保持其价值和性能。
- 资产处置:涉及资产的出售、转让、报废或回收等,以优化资产组合和释放资本。
- 风险管理:识别、评估和控制与资产相关的各种风险,如市场风险、信用风险、操作风险等。
- 合规性:确保资产管理活动遵守相关法律法规和内部政策。
国家高度重视
《数字中国发展报告(2022年)》显示,2022年我国数字经济规模已超过50万亿元,数字经济占GDP比重达到41.5%,位居世界第二位。数据已成为第五大生产要素。数据资产,作为经济社会数字化转型进程中的新兴资产类型,正日益成为推动数字中国建设和加快数字经济发展的重要战略资源。
- 2020年08月26日,财政部印发《关于加强行政事业单位固定资产管理的通知》
- 2021年2月1日,国务院印发《行政事业性国有资产管理条例》
- 2022年,中共中央、国务院印发《关于构建数据基础制度更好发挥数据要素作用的意见》
- 2023年,中共中央、国务院印发《数字中国建设整体布局规划》
- 2023年12月31日,财政部印发《关于加强数据资产管理的指导意见》
- 财政部、住房城乡建设部、工业和信息化部、公安部、交通运输部、水利部于2024年7月23日印发《市政基础设施资产管理办法(试行)》
- 国务院关于2022年度国有资产管理情况的综合报告——2023年10月21日在第十四届全国人民代表大会常务委员会第六次会议上
数智化资产管理迫在眉睫
(一)企业国有资产(不含金融企业)
2022年,中央企业资产总额109.4万亿元、负债总额73.7万亿元、国有资本权益21.8万亿元,平均资产负债率67.3%。2022年,地方国有企业资产总额230.1万亿元、负债总额145.0万亿元、国有资本权益72.9万亿元,平均资产负债率63.0%。汇总中央和地方情况,2022年,全国国有企业资产总额339.5万亿元、负债总额218.6万亿元、国有资本权益94.7万亿元,平均资产负债率64.4%。
(二)金融国有资产
2022年,中央国有金融资本权益19.1万亿元,中央金融企业资产总额261.6万亿元、负债总额234.7万亿元。2022年,地方国有金融资本权益8.5万亿元,金融企业资产总额139.3万亿元、负债总额123.5万亿元。汇总中央和地方情况,2022年,全国国有金融资本权益27.6万亿元,金融企业资产总额400.9万亿元、负债总额358.2万亿元。
(三)行政事业性国有资产
2022年,中央行政事业性国有资产总额6.5万亿元、负债总额2.0万亿元、净资产4.5万亿元。其中,行政单位资产总额1.4万亿元,事业单位资产总额5.1万亿元。2022年,地方行政事业性国有资产总额53.3万亿元、负债总额10.4万亿元、净资产42.9万亿元。其中,行政单位资产总额20.2万亿元,事业单位资产总额33.1万亿元。汇总中央和地方情况,2022年,全国行政事业性国有资产总额59.8万亿元、负债总额12.4万亿元、净资产47.4万亿元。其中,行政单位资产总额21.6万亿元,事业单位资产总额38.2万亿元。
(四)国有自然资源资产
截至2022年末,全国国有土地总面积52360.5万公顷。其中,国有建设用地1818.6万公项、国有耕地1957.5万公顷、国有园地239.3万公顷、国有林地11261.0万公项、国有草地19740.5万公项、国有湿地2175.3万公顷。根据«联合国海洋法公约»有关规定和我国主张,管辖海域面积约300万平方公里。2022年,全国水资源总量27088.1亿立方米。
将大模型应用于资产管理的相关技术
- 自然语言处理(NLP):大模型通过深度学习算法,如Transformer,理解和生成自然语言文本,执行文本生成、翻译、总结、问答等任务。
- 机器学习和深度学习:利用机器学习算法和神经网络,如循环神经网络(RNN)和长短期记忆网络(LSTM),处理和分析大量金融数据。
- 数据预处理:包括数据摄取、数据变换和下游连接,使用OCR模型和正则表达式等工具处理非结构化文本数据。
- 向量数据库:将文档及其嵌入存储在向量数据库中,以便LLMs能够更快地检索和处理数据。
- LLM编程框架:提供工具和抽象组件,用于构建基于LLMs的应用程序,包含预定义的链(chain)用于编排不同的组件并实现复杂任务。
- 时间序列分析:使用深度学习模型如LSTM网络和CNN捕捉时间序列数据中的时间依赖性和异常。
- 金融推理:通过处理和综合大量的金融数据,支持战略财务规划、投资建议、咨询服务和决策制定。
- 基于代理的建模(ABM):模拟复杂系统,特别是金融市场中的多样化行为,LLMs增强代理的认知功能,实现更现实和自适应的模拟。
- 智能合约的模糊测试:利用大语言模型指导智能合约的模糊测试活动,优化智能合约的自动化安全分析。
- 多模态数据处理:处理包括图像、音频和视频在内的多模态数据,整合非语言线索到情感分析中。
基于大模型的技术案例
使用大型语言模型(LLMs)进行资产管理的内容主要包括:
- 金融投资研究:LLMs能够快速准确地从大量市场数据、财务报告和宏观经济指标中提取关键信息,帮助资产管理公司进行数据分析和总结,从而加快数据整理速度并减少人为干预错误。例如,可以使用LLMs来分析公司报告中的情绪,新闻和电话会议,帮助投资者更好地理解公司的情绪和潜在的未来发展趋势。
- 风险管理:LLMs通过复杂的数据分析和模式识别来预测和评估各种类型的风险。例如,LLMs可以迅速分析特定资产类别的市场波动性的历史趋势和相关新闻报告,为风险评估过程提供定量和定性支持。
- 客户服务和咨询:LLMs的应用显著提高了用户交互体验,能够理解客户的具体需求和情况,提供针对性的响应或建议,从而大大提高客户满意度。
- 监管合规:LLMs能够解释复杂的监管文件,协助资产管理公司确保其业务运营符合各种法律要求。例如,当新的金融法规出台时,LLMs可以迅速总结主要变化和潜在影响,帮助公司快速适应法律环境的变化。
- 投资管理:LLMs可以分析市场数据并预测未来价格走势,这些信息可以用来通知交易策略。LLMs不仅对对冲基金有益,对资产管理行业的其他参与者,如资产经理和养老基金也有益。
招商银行资管领域大模型探索实践
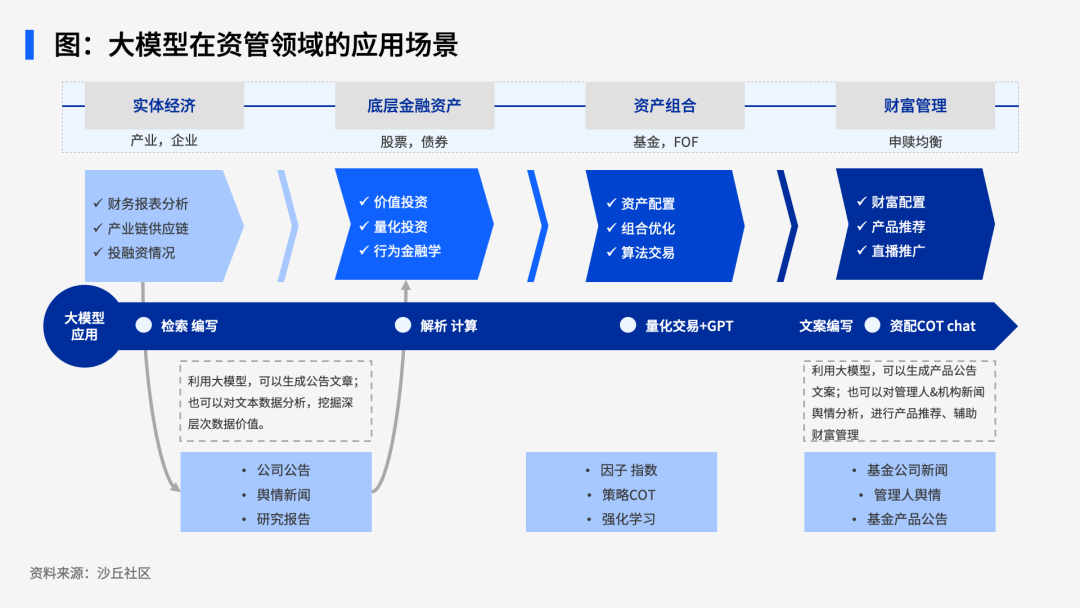
基于大模型的生成和理解能力,可以在资产管理业务的整个链条中进行应用,例如在实体经济和底层金融资产中,利用大模型的生成能力可以完成研报的写作、检索,利用大模型的理解能力对已有研报可以进行解析、理解、摘要、脱水,挖掘深层次数据价值;在资产组合层面,大模型可以进行因子提取、指数辅助编制、策略COT辅助实现;在财管管理阶段,大模型可以解析基金公司新闻、管理人舆情、基金产品公告等信息,通过资配的逻辑对非专业投资客户进行产品推荐,辅助财富管理。
平安在保险资管领域的大模型应用
基于保险资管场景的特点和实战经验,平安资管总结了大模型应用的几点原则:
第一,不能依赖于模型自有记忆,基于给定素材和知识库。模型记忆主要来自于预训练语料,但语料的时效性往往较弱,且准确性无法满足专业人士的需求。因此使用用户输入的文本、搜索结果或知识库查询结果。
第二,避免参与决策类问题。人做不好的事情不要交给模型做,人能做好的事情可以考虑让机器提效。
第三,聚焦小颗粒耗时任务,发挥信息处理优势。基于给定素材,只让大模型做信息处理,尽量处理简单重复的任务,保证流程可控,避免出现幻觉等问题。

东方资管投研场景大模型应用实践
基金经理、研究员每天面对海量的金融信息,难以快速精准获取有价值的信息。公募基金管理费、托管费降费,需要降低公司运营成本。随着大模型能力的逐渐进步,为大模型应用提供技术基础。作为资产管理公司,投研方向的知识问答是大模型最具业务价值的探索方向。
东方资管将大模型用于投研方向的知识问答场景,联合东方证券开发基于大模型的AI投研助理平台(东方红智能小牛)。本案例通过介绍东方资管的模型选择、知识库检索增强等工作,为其他金融机构提供参考。
Morgan Stanley
和 OpenAI 合作推出了一款基于 GPT-4 技术的聊天机器人,并利用该机器人管理其面向客户的庞大知识库。计划部署一个聊天应用程序,利用OpenAI的GPT-4(世界上最大的LLM)来整理超过100,000份内部文件的数据。这种使用生成性AI扩展了Morgan Stanley在私有控制生态系统中的智力资本。
Stripe
使用LLMs来改善客户支持和用户审核。
美国人工智能研究公司OpenAI已与支付公司Stripe达成合作,将其生成式人工智能(AI)产品ChatGPT和Dall-E货币化。
据报道,这两家公司的合作是双向的。OpenAI选择Stripe的金融基础设施平台,将其生成式AI技术商业化,而Stripe则将把OpenAI新一代大型语言模型GPT-4嵌入到其产品和服务中。
Orion
Orion already started using ChatGPT, including comparing and contrasting portfolios, refining marketing content, responding to RFPs and more.
发展趋势
资产管理的最新趋势体现在以下几个方面:
- 数字化和智能化:资产管理行业正通过大模型技术和数据分析工具,提高资产管理的效率和决策质量。这包括使用人工智能、机器学习和区块链技术来优化投资策略和风险管理。
- 监管合规:随着监管环境的变化,资产管理公司需要遵守更严格的法规,如资管新规,这推动了行业向更健康、更规范的方向发展。
- 可持续投资:环境、社会和治理(ESG)投资的需求日益增长,资产管理公司需要推出更多责任投资及可持续投资产品,同时避免“绿化”陷阱,满足投资者在可持续投资方面的需求。
- 全球资产配置:资产管理公司正在寻求全球资产配置的机会,以分散风险并寻找更高回报的投资机会。
- 客户导向的服务:资产管理行业正从产品销售导向转向更加以客户为中心的服务模式,提供更加个性化和定制化的资产管理解决方案。
- 科技和数据的应用:资产管理行业正在加强科技和数据的应用,以提高投资决策的效率和精准度,同时利用大数据和人工智能技术来分析市场趋势和客户行为。
- 风险管理的强化:在市场波动和不确定性增加的背景下,资产管理公司更加重视风险管理,以保护投资者的资产并确保资产的稳健增长。
refs:
https://m.yunnan.cn/system/2024/01/18/032912939.shtml
http://www.npc.gov.cn/npc//c2/c30834/202310/t20231027_432641.html
https://www.gov.cn/zhengce/content/2021-03/17/content_5593484.htm
https://www.gov.cn/zhengce/zhengceku/2020-09/08/content_5541517.htm
https://www.shaqiu.cn/article/xadNYKbGVERB
https://baijiahao.baidu.com/s?id=1778266213650461199&wfr=spider&for=pc
https://www.fromgeek.com/ai/523104.html
https://www.wealthmanagement.com/technology/wealthtech-firms-and-advisors-ai-has-entered-chat