整体框架
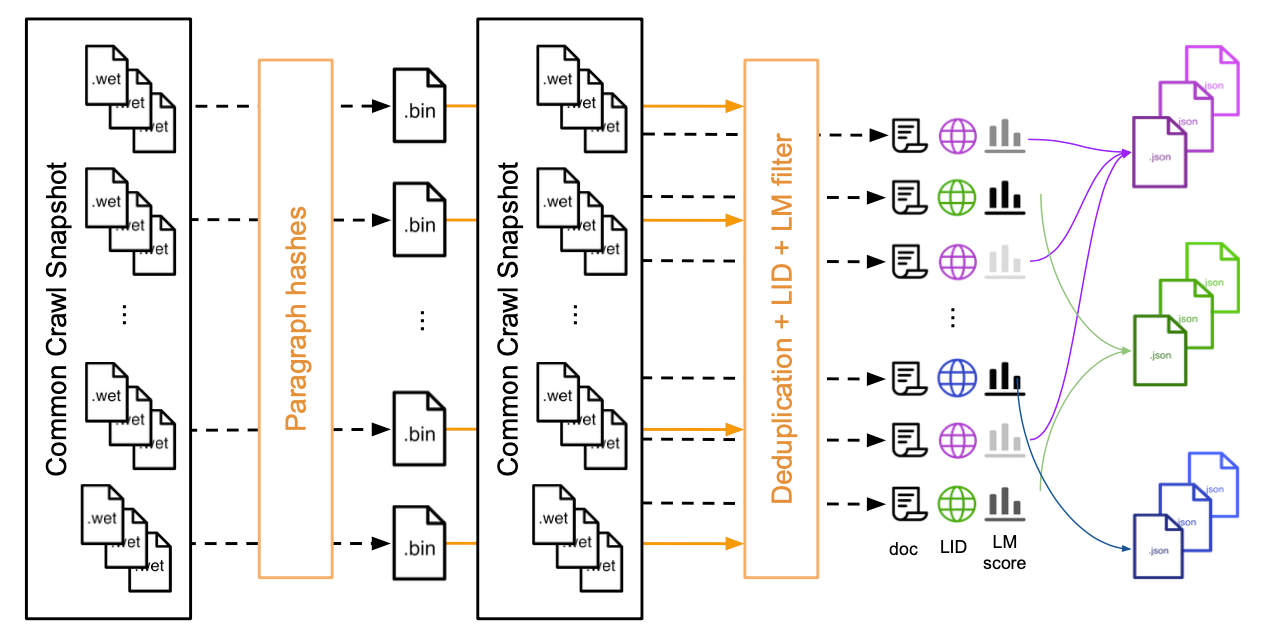
下图展示了用于下载和处理常见网络爬虫数据快照的整个pipline。
首先下载所有WET文件并分组保存为二进制文件,然后计算所有段落的哈希。
接着独立处理WET文件的每个文档:使用二进制文件对段落进行语言识别并计算语言模型困惑度从而删除重复数据。
最后按语言和困惑度分数将文档重新分组为json文件。
数据获取和预处理
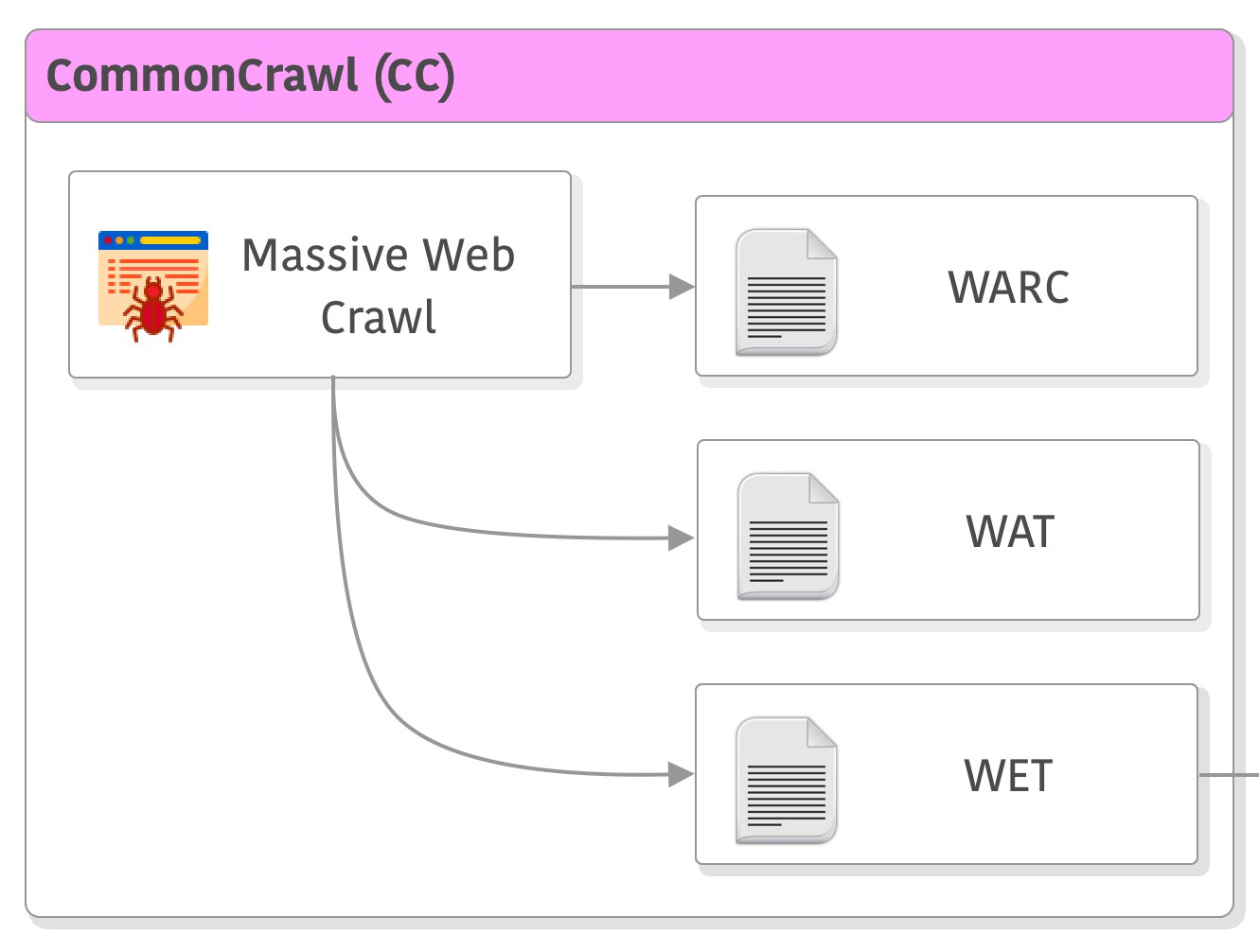
Common Crawl每月都会发布通过随机浏览和采样URL获得的网络快照。每个网页都有不同的可用格式:原始(WARC)、UTF-8文本(WET)和元数据(WAT)。
- WARC(Web ARChive):它是一种用于存储和传输Web资源(例如HTML页面,图像和视频文件等)的文件格式。 WARC文件通常包含HTTP响应和元数据,用于记录Web爬虫收集的信息。
- WAT(Web Archive Transformation):它是一种元数据文件格式,用于描述WARC文件中记录的Web内容。 WAT文件通常包含URL,域名和其他有关记录的元数据信息。
- WET(Web Extraction Toolkit):它是一种将HTML页面转换为文本格式的文件格式。 WET文件通常包含从HTML页面中提取的文本内容,但不包括图像和其他资源。
特点:1. 每月快照之间几乎没有内容重叠。2. 完整的数据包由8年来收集的数PB的数据组成。3. 网页是从整个网站上无限制地抓取的,包含有许多不同的语言。4. 文本的质量也有很大的差异。
每个快照包含 20 到 30TB 的未压缩纯文本,相当于大约 30 亿个网页(例如,2019 年 2 月的快照包含 24TB 的数据)。可以独立下载和处理每个快照。对于每个快照,将 WET 文件重新分组为每个 5GB 的shard。
这些shards被保存到JSON文件中,其中一个条目对应一个网页。
去重
包括删除快照中不同网页中的重复段落,因为它们占文本的 70%。
首先通过将所有字符小写、用占位符(即 0)替换数字并删除所有 Unicode 标点符号和重音符号来标准化每个段落。
然后,重复数据删除通过两个独立的步骤完成。
首先,对于每个shard,我们计算每个段落的哈希码并将它们保存到二进制文件中。我们使用规范化段落的 SHA-1 的前 64 位作为密钥。
然后,我们通过将每个shard与所有二进制文件或其子集进行比较来消除重复数据。
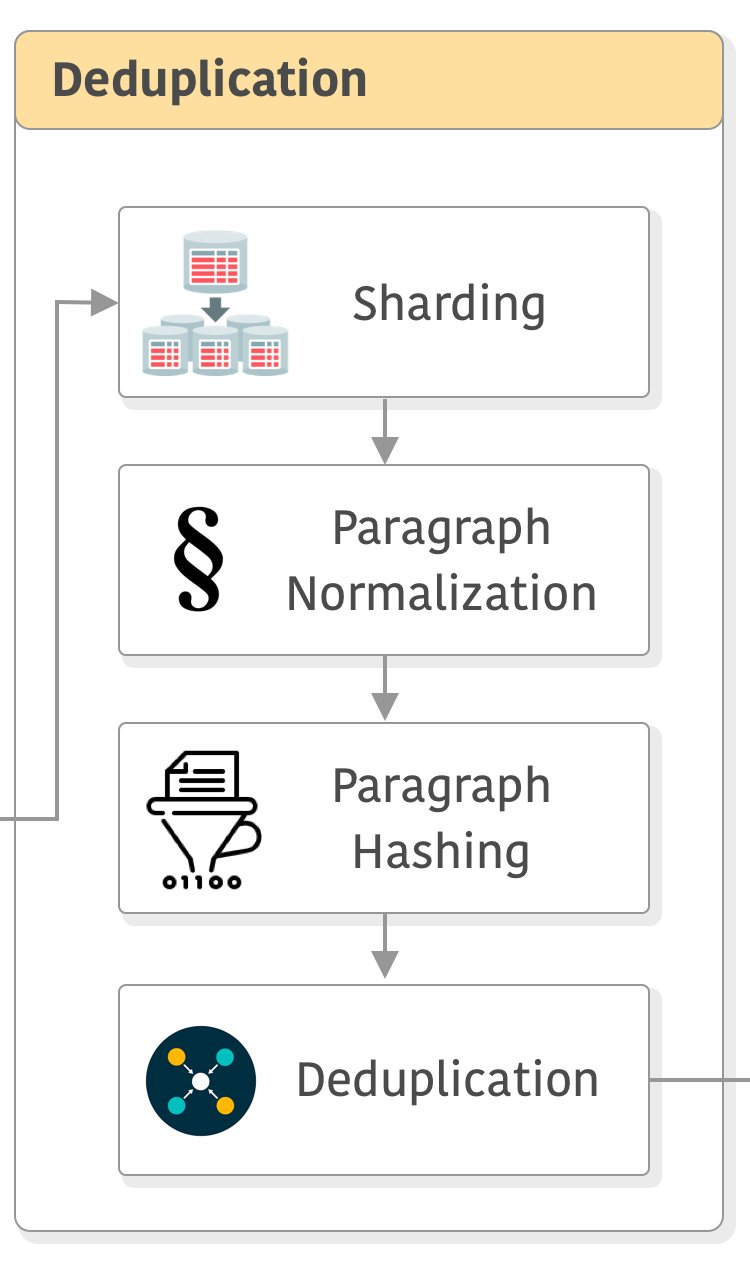
这些步骤对于每个shard来说都是独立的,因此可以进行分布式。除了删除网络副本之外,此步骤还删除了许多样板文件,例如导航菜单、cookie 警告和联系信息。
特别是,它从其他语言的网页中删除了大量的英语内容。
这使得我们pipline的下一步的语言识别更加强大。
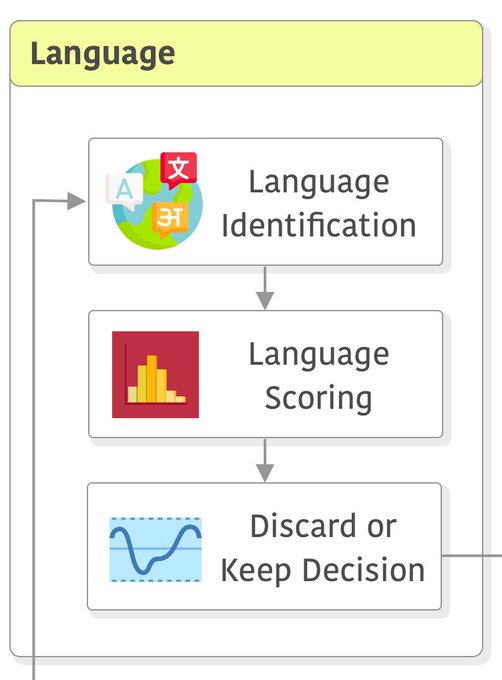
语言识别
包括按语言拆分数据。
这里使用来自 fastText ,改语言分类器在Wikipedia,Tatoeba和SETimes上进行了训练。
它使用字符 n-gram 作为特征,并使用分层softmax。
它支持 176 种语言,并在 [0, 1] 范围内为每种语言输出分数。它在单个 CPU 内核上每秒处理 1k 个文档。
对于每个网页,我们计算出最可能的语言和相应的分类器分数。如果该分数高于0.5,我们将文档分类为相应的语言。
否则语言没有明确标识,我们丢弃相应的页面。
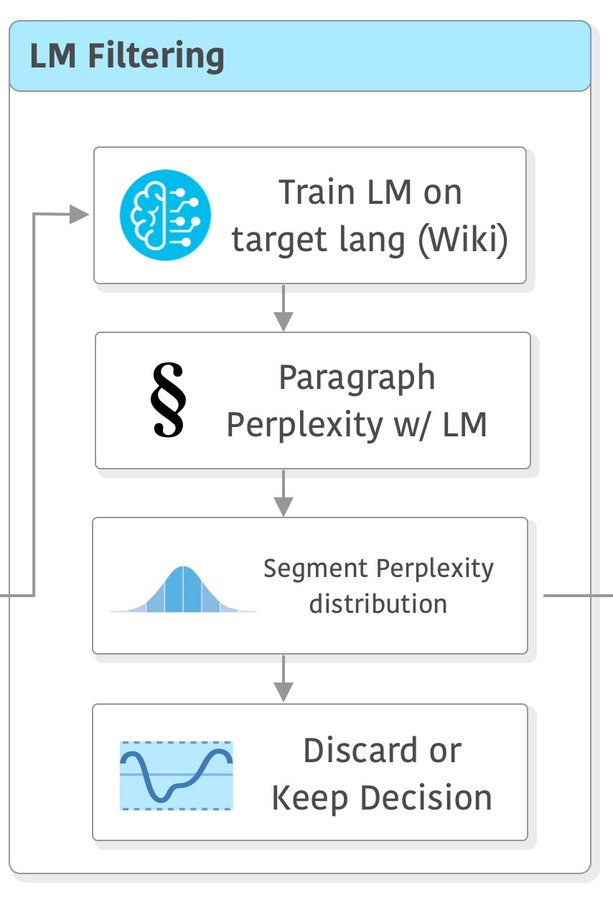
基于语言模型的质量过滤
至此仍然存在内容质量低下的文档。
过滤掉这些样本的一种方法是计算网页与目标域(例如维基百科)的相似度分数。
此处建议使用在目标领域训练的语言模型的困惑度作为质量得分。
更准确地说,对于每种语言,根据目标域的数据训练一个tokenizer和语言模型。
这里使用 KenLM 库中实现的 5-gram Kneser-Ney 模型,因为它可以高效地处理大量数据。
然后,对数据集中的每个页面进行tokenization,并使用语言模型计算每个段落的困惑度。
困惑度越低,数据越接近目标域。
在此步骤结束时,每种语言被分平均地分为头、中、尾三个部分,对应于困惑度分数。
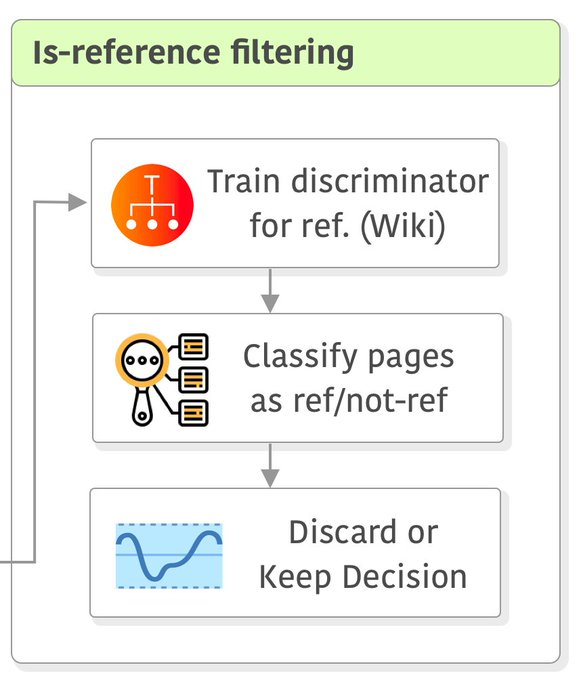
进一步过滤
通过维基百科参考的页面和随机抽样的页面,训练一个MLP作为discriminator,来判断输入的页面是否为维基百科参考页面。
训练完成后通过改判别器丢弃一部分非参考页面。
reference:
Wenzek, Guillaume, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. “CCNet: Extracting high quality monolingual datasets from web crawl data.” arXiv preprint arXiv:1911.00359 (2019).
https://www.datalearner.com/blog/1051682313146748