什么是关联规则
关联规则是一种条件语句,它们帮助揭示数据库、关系数据库或其他信息库中看似无关数据之间的关系。关联规则用于发现经常一起使用的对象之间的关系。关联规则的应用包括购物篮数据分析、分类、交叉营销、聚类、目录设计和领先损失分析等。
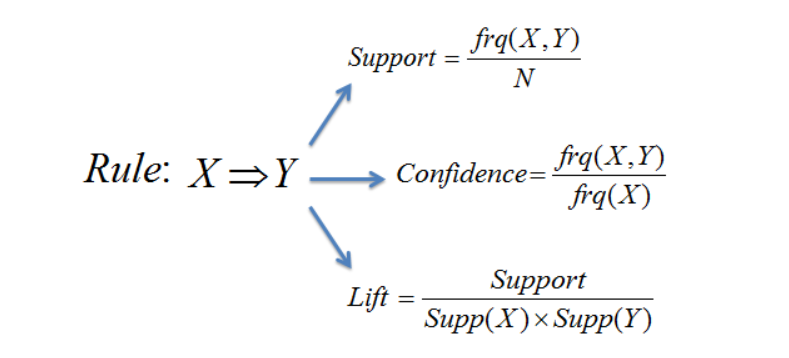
关联规则使用两个基本标准:支持度(support)和置信度(confidence)。它通过分析数据中的频繁使用的”如果/那么”模式来识别关系和生成规则。通常,关联规则需要同时满足用户指定的最小支持度和用户指定的最小置信度。
计算方法如下:
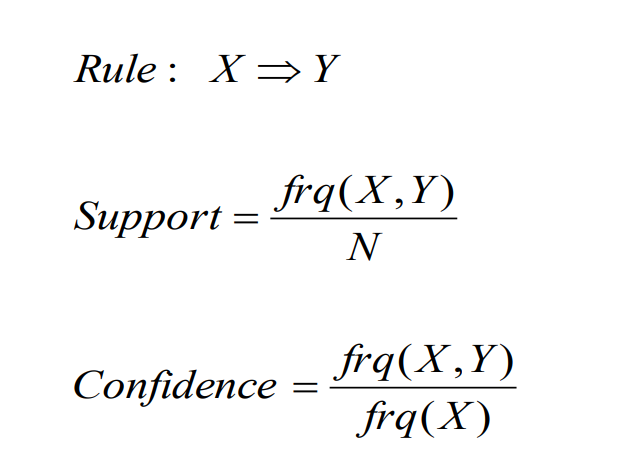
AIS Algorithm
AIS算法由Agrawal、Imielinski和Swami首次提出的用于挖掘关联规则的算法。它专注于提高数据库的质量以及处理决策支持查询所需的必要功能。计算流程如下:
- 首先,候选项集是通过扫描数据库获得。
- 对于每个事务,确定此事务中包含上一步的大项集是哪一项。
- 通过将这些大型项集与此事务中的其他项一起扩展,生成新的候选项集。
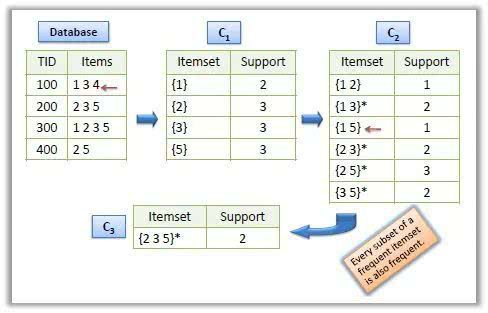
案例如下:
首先生成候选集{1}{2}{3}{5},支持度为2,3,3,3。下一步生产两个候选项集{1,3}{1,4}….{1,5},对应的支持度为2,1,…,1.这里当支持度大于等于2时记录为大项集{1,3}{2,3}{2,5}{3,5},下一步生产三个组合的项集,{1,3,4}{2,3,5}{1,3,5},此时发现{2,3,5}是最终的最大项集。
SETM Algorithm
在SETM算法中,候选项目集在扫描数据库时即时生成,但在扫描结束时进行计数。然后,以与AIS算法相同的方式生成新的候选项目集,但生成交易的事务标识符TID与候选项目集一起以顺序结构保存。它将候选生成过程与计数过程分开。在扫描结束时,通过聚合顺序结构来确定候选项目集的支持计数。SETM算法具有与AIS算法相同的缺点。另一个缺点是,对于每个候选项目集,其条目数量与其支持值一样多。计算流程如下:
- 候选项集将在数据库被扫描时动态生成,但在传递结束时进行计数。
- 新的候选项集的生成方式与AIS算法相同,但是生成事务的TID与候选项集保存在顺序结构中。如下图所示。
- 在传递结束时,通过排序和聚合(sorting and aggregating)这个顺序结构来确定候选项集的支持数。

首先生成候选集{1}{2}{3}{5},支持度分别为2,3,3,3。下一步生产两个候选项集{1,3}{1,4}….{2,5},对应的TID2进行排序获得c2.进行聚合操作获得c3,发现有{1,3,4}{2,3,5}{1,3,5},{2,3,5}为最大项集。
Apriori Algorithm
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。
基本思想:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样;然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。
AprioriTid Algorithm
AprioriTid算法对Apriori算法做了调整,它的特点是在第一次遍历数据库D之后,就不再使用数据库来计算支持度,而是用集合Ck来完成。

基本思想:跟Apriori算法的步骤基本相同,只是在第一次通过之后,数据库不用于计算候选项集;生成另一个集合C’,其中每个成员具有每个事务的TID以及该事务中存在的大项集,这个集用于计算每个候选项集。
FP-Growth Algorithm
又称FP-tree算法,是在不使用候选代的情况下查找频繁项集的另一种方法,从而提高了性能。其核心是使用名为频繁模式树(FP-tree)的特殊数据结构,保留了项集关联信息。
FP树是一种存储数据的树结构,如下图所示,每一路分支表示数据集的一个项集,数字表示该元素在某分支中出现的次数。
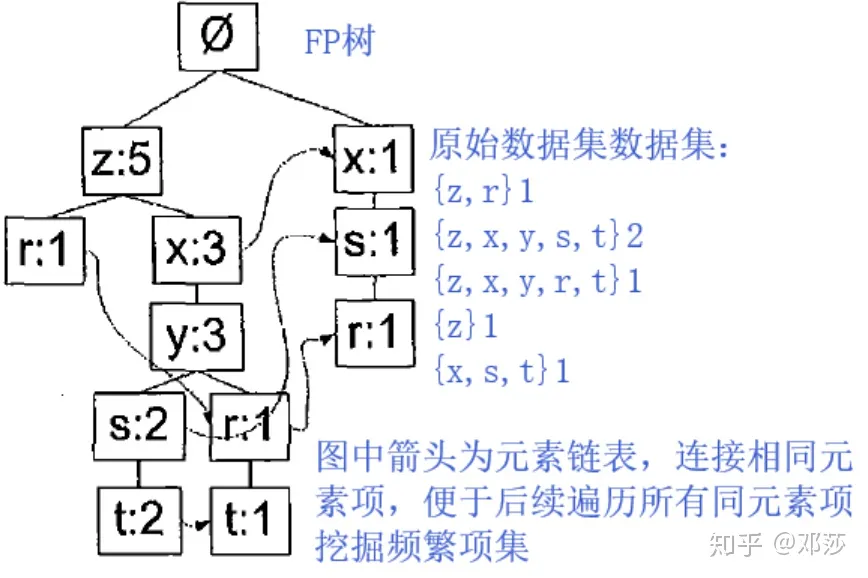
算法过程如下:
- 构建FP树
- 遍历数据集获得每个元素项的出现次数,去掉不满足最小支持度的元素项
- 读入每个项集并将其添加到一条已存在的路径中,若该路径不存在,则创建一条新路径(每条路径是一个无序集合)
- 从FP树中挖掘频繁项集
- 从FP树中获得条件模式基
- 利用条件模式基构建相应元素的条件FP树,迭代直到树包含一个元素项为止
未来发展与挑战
关联规则挖掘在数据挖掘领域具有广泛的应用前景,但同时也面临着一些挑战。未来的发展方向和挑战包括:
- 大数据处理:随着数据规模的增加,传统的关联规则挖掘算法在处理能力和效率方面面临挑战。未来的研究需要关注大数据处理技术,以提高算法的处理能力和效率。
- 多源数据集成:多源数据集成是关联规则挖掘中的一大挑战,因为不同数据源之间可能存在格式、质量、语义等差异。未来的研究需要关注多源数据集成技术,以提高关联规则挖掘的准确性和可靠性。
- 异构数据处理:异构数据是指不同类型的数据(如文本、图像、音频等)。未来的研究需要关注异构数据处理技术,以挖掘这些数据中的关联规则。
- 私密和安全:随着数据保护和隐私问题的重视,关联规则挖掘需要关注数据的私密和安全。未来的研究需要关注数据掩码、数据脱敏等技术,以保护数据的安全和隐私。
- 智能推荐系统:关联规则挖掘可以应用于智能推荐系统,为用户提供个性化的推荐。未来的研究需要关注智能推荐系统的发展,以提高推荐系统的准确性和用户体验。
方法比较
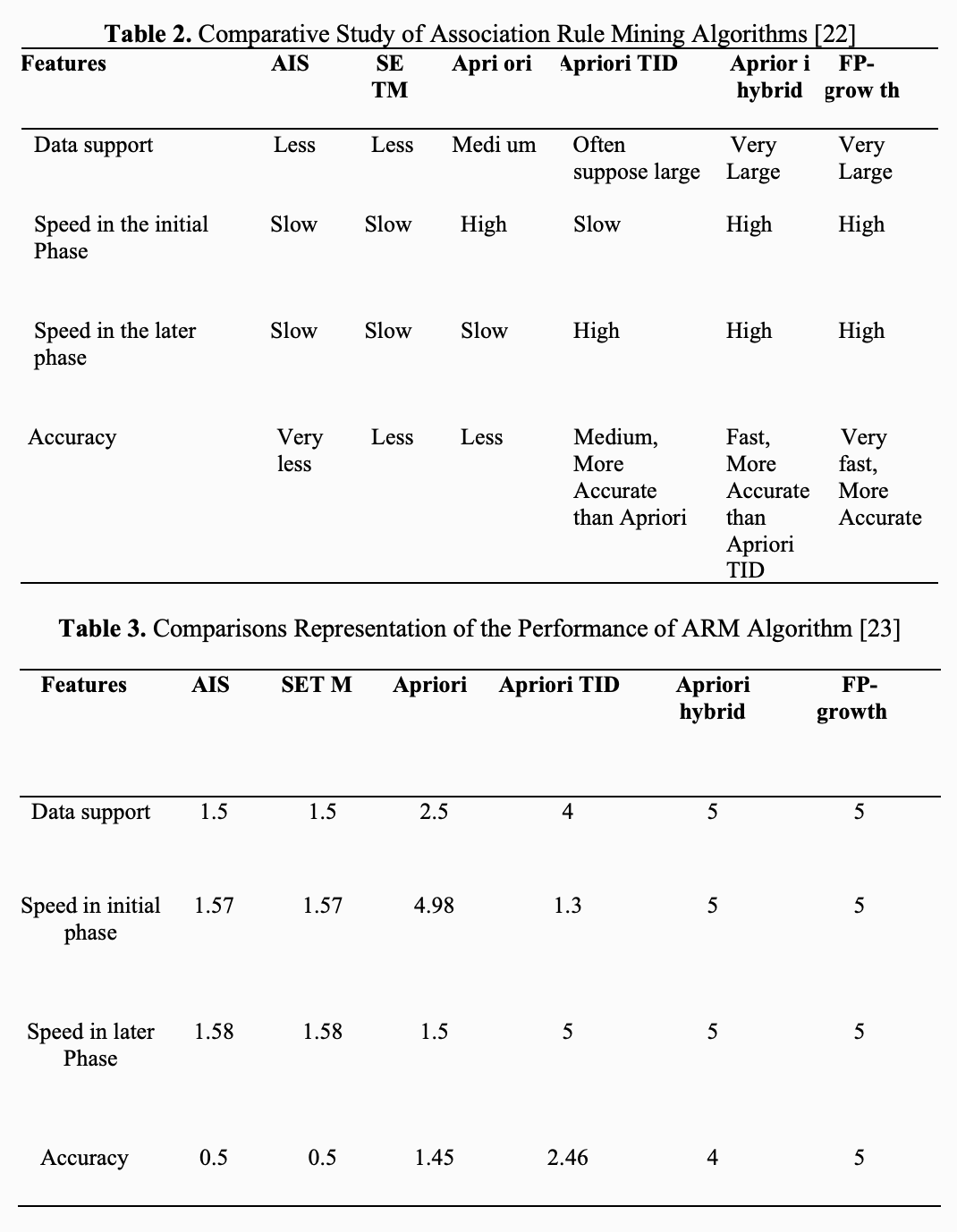
ref:
https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=d4058d9f3f66c53ddea776c974fbd740afd994b4
https://www.jiqizhixin.com/graph/technologies/d44f694a-2363-4fd1-93d8-a77983bff15c
https://www.163.com/dy/article/FD5U7JV60528OOR6.html
https://zhuanlan.zhihu.com/p/62919869
https://iopscience.iop.org/article/10.1088/1757-899X/1099/1/012032/pdf