BLEU
BLEU (Bilingual Evaluation Understudy)是一种基于n-gram精度的评估指标,它通过计算机器翻译结果和参考翻译之间的n-gram匹配度来评估机器翻译的质量。
BLEU(Bilingual Evaluation Understudy)是一种评估机器翻译质量的方法,特别是它如何接近人类翻译的程度。BLEU分数是基于机器翻译输出与一组参考翻译之间的重叠程度来计算的。以下是BLEU分数的计算步骤:
选择N-gram:
- 确定你想要使用的N-gram大小。常见的选择是1-gram(单个词),2-gram(两个连续词),3-gram,以此类推,直到n-gram。
计算N-gram精确度:
- 对于每个N-gram大小,计算机器翻译输出中的N-gram与参考翻译中N-gram的精确度。精确度是指机器翻译输出中正确的N-gram数量除以机器翻译输出中N-gram的总数。
应用Brevity Penalty(BP):
- 如果机器翻译输出比任何参考翻译都短,那么它可能会得到较低的BLEU分数,因为短的输出可能更容易与参考翻译匹配。BP用于惩罚这种短输出:
$$
\text{BP} =
\begin{cases}
1 & \text{if } c > \text{ref} \
\exp(1 - \frac{\text{ref}}{c}) & \text{if } c \leq \text{ref}
\end{cases}
$$ - 其中,$c$是机器翻译输出中的词数,$ref$是最短参考翻译中的词数。
- 如果机器翻译输出比任何参考翻译都短,那么它可能会得到较低的BLEU分数,因为短的输出可能更容易与参考翻译匹配。BP用于惩罚这种短输出:
计算加权和:
- 对于每个N-gram大小,计算其精确度与权重的乘积。权重通常按N-gram大小递减,例如,对于1-gram到4-gram,权重可能是(0.25, 0.25, 0.25, 0.25)。
计算几何平均值:
- 对所有N-gram的加权精确度进行几何平均,以得到最终的BLEU分数:
$$
\text{BLEU} = BP \times \exp\left(\sum_{n=1}^{N} \frac{w_n \cdot p_n}{\sum_{n=1}^{N} w_n}\right)
$$ - 其中,$(w_n)$是第n个N-gram大小的权重,$p_n$是第n个N-gram大小的精确度。
- 对所有N-gram的加权精确度进行几何平均,以得到最终的BLEU分数:
输出结果:
- 最终的BLEU分数范围从0到1,分数越高表示机器翻译的质量越接近人类翻译。
BLEU分数是一个快速且广泛接受的评估机器翻译质量的方法,但它也有局限性,例如它不能很好地评估语义的准确性和流畅性。因此,BLEU分数通常与其他评估方法一起使用,以获得更全面的翻译质量评估。
ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种主要用于评估自动文摘和机器翻译的评估指标,它通过计算机器生成的摘要或翻译结果和参考摘要或翻译之间的n-gram重叠度来评估生成结果的质量。ROUGE指标主要关注评估生成的摘要或翻译与一组参考摘要或翻译之间的重叠程度。以下是几种常见的ROUGE指标的计算方法:
ROUGE-N (N-gram Recall)
计算N-gram:
- 对于每个参考摘要和生成的摘要,分别计算N-gram(连续的N个词)。
确定匹配的N-gram:
- 找出生成的摘要中的N-gram与参考摘要中的N-gram相匹配的数量。
计算召回率:
- 召回率(Recall)是生成的摘要中匹配的N-gram数量与参考摘要中N-gram总数的比例:
$$
\text{ROUGE-N Recall} = \frac{\text{匹配的N-gram数量}}{\text{参考摘要中的N-gram总数}}
$$
- 召回率(Recall)是生成的摘要中匹配的N-gram数量与参考摘要中N-gram总数的比例:
ROUGE-L (Longest Common Subsequence)
计算最长公共子序列(LCS):
- 确定生成的摘要和参考摘要之间的最长公共子序列。
计算长度比:
- 将LCS的长度与参考摘要和生成的摘要的长度进行比较。
计算F-measure:
- F-measure是精确度和召回率的调和平均数,用于评估ROUGE-L:
$$
\text{ROUGE-L F-measure} = \frac{(1 + \beta^2) \cdot \text{ROUGE-L Recall} \cdot \text{ROUGE-L Precision}}{\beta^2 \cdot \text{ROUGE-L Recall} + \text{ROUGE-L Precision}}
$$ - 其中,$\beta$是一个权重因子,通常取1,使得精确度和召回率的权重相等。
- F-measure是精确度和召回率的调和平均数,用于评估ROUGE-L:
ROUGE-S (Skip-Bigram Co-occurrence)
比如:”他每天都会去公园散步。”
在这个例子中,如果我们考虑bigram(两个连续词),句子中的”每天”和”散步”是连续的,而在生成句子中它们不是连续的。但是,如果我们考虑skip-bigram,我们可以看到”散步”和”公园”在两个句子中都是成对出现的,尽管它们在原文中不相邻。这表明生成的句子在语义上与参考句子保持了一定的连贯性。
计算skip-bigram:
- Skip-bigram是指在文本中不连续出现的两个词,但它们在另一个文本中是连续的。
确定匹配的skip-bigram:
- 找出生成的摘要中的skip-bigram与参考摘要中的skip-bigram相匹配的数量。
计算召回率:
- 召回率是生成的摘要中匹配的skip-bigram数量与参考摘要中skip-bigram总数的比例。
METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering)是一种综合考虑精度、召回率和语法流畅度的评估指标,它通过比较机器翻译结果和参考翻译在单词级别的匹配度来评估机器翻译的质量。METEOR考虑了词汇的匹配、句子结构、词形变化以及同义词。METEOR与BLEU分数不同,它不仅关注词的重叠,还关注词的顺序和意义。以下是METEOR分数的基本计算步骤:
- 语义相似度计算:使用语义相似度算法比较摘要中的每个单词与原文中相应单词的语义相似度。常用的语义相似度算法包括基于词向量、知识图谱和深度学习的方法。
- 文本对齐度计算:评估摘要中的句子与原文中的句子之间的文本对齐度。常用的文本对齐度算法包括基于编辑距离、余弦相似度和句法结构的方法。
- 平均精度计算:根据语义相似度和文本对齐度的结果,计算每个单词的平均精度。平均精度的计算方式是将语义相似度和文本对齐度的结果相加,并除以总的相关单词数。
- 最终得分计算:将平均精度扩展到整个摘要,计算METEOR得分。可以通过将每个单词的平均精度相加,并除以摘要中的总单词数,得到最终的METEOR得分。
METEOR分数的计算公式大致如下:
该算法首先计算 unigram 情况下的准确率P和召回率R(计算方式与BLEU、ROUGE类似),得到调和均值F值:

Meteor的特别之处在于,它不希望生成很“碎”的译文:比如参考译文是“A B C D”,模型给出的译文是“B A D C”,虽然每个unigram都对应上了,但是会受到很严重的惩罚。惩罚因子的计算方式为:
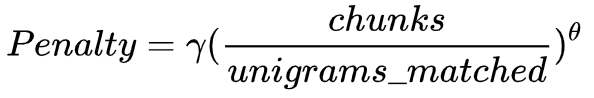
在评价句子流畅性的时候,用了 chunk 的概念(候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk,这个对齐算法是一个有点复杂的启发式 beam search),chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致。 unigrams_matched表示匹配上的unigram个数。
最后,METEOR计算为对应最佳候选译文和参考译文之间的准确率和召回率的调和平均:
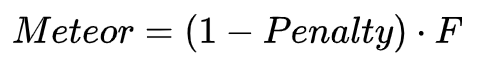
用于机器翻译评测时,通常取 $\alpha$ =3,$\gamma$=0.5,$\theta$=3。
Refs:
https://blog.csdn.net/m0_62554628/article/details/136645353
https://developer.baidu.com/article/details/3121202