方法
使用包\usepackage{longtable},然后使用\begin{longtable}...\end{longtable}代替tabular即可
注意**不能在一个表格上同时使用table和longtable**,比如\begin{table}\begin{longtable}...\end{longtable}\end{table},这会使longtable无法分页。
栗子
1 | \begin{center} |
使用包\usepackage{longtable},然后使用\begin{longtable}...\end{longtable}代替tabular即可
注意**不能在一个表格上同时使用table和longtable**,比如\begin{table}\begin{longtable}...\end{longtable}\end{table},这会使longtable无法分页。
1 | \begin{center} |
这是一篇W3school Schema 教程学习笔记。
XML Schema 是基于 XML 的 DTD 替代者。XML Schema 描述 XML 文档的结构。XML Schema 语言也称作 XML Schema 定义(XML Schema Definition,XSD)。
1 | <xs:element name="xxx" type="yyy"/> |
1 | <xs:attribute name="xxx" type="yyy"/> |
| 限定 | 描述 |
|---|---|
| enumeration | 定义可接受值的一个列表 |
| fractionDigits | 定义所允许的最大的小数位数。必须大于等于0。 |
| length | 定义所允许的字符或者列表项目的精确数目。必须大于或等于0。 |
| maxExclusive | 定义数值的上限。所允许的值必须小于此值。 |
| maxInclusive | 定义数值的上限。所允许的值必须小于或等于此值。 |
| maxLength | 定义所允许的字符或者列表项目的最大数目。必须大于或等于0。 |
| minExclusive | 定义数值的下限。所允许的值必需大于此值。 |
| minInclusive | 定义数值的下限。所允许的值必需大于或等于此值。 |
| minLength | 定义所允许的字符或者列表项目的最小数目。必须大于或等于0。 |
| pattern | 定义可接受的字符的精确序列。 |
| totalDigits | 定义所允许的阿拉伯数字的精确位数。必须大于0。 |
| whiteSpace | 定义空白字符(换行、回车、空格以及制表符)的处理方式。 |
下面的例子定义了带有一个限定且名为 “age” 的元素。age 的值不能低于 0 或者高于 120:
1 | <xs:element name="age"> |
如需把 XML 元素的内容限制为一组可接受的值,我们要使用枚举约束(enumeration constraint)。
下面的例子定义了带有一个限定的名为 “car” 的元素。可接受的值只有:Audi, Golf, BMW:
1 | <xs:element name="car"> |
如需把 XML 元素的内容限制定义为一系列可使用的数字或字母,我们要使用模式约束(pattern constraint)。
下面的例子定义了带有一个限定的名为 “letter” 的元素。可接受的值只有小写字母 a - z 其中的一个:
1 | <xs:element name="letter"> |
下一个例子定义了带有一个限定的名为 “initials” 的元素。可接受的值是大写字母 A - Z 其中的三个:
1 | <xs:element name="initials"> |
下一个例子也定义了带有一个限定的名为 “initials” 的元素。可接受的值是大写或小写字母 a - z 其中的三个:
1 | <xs:element name="initials"> |
下一个例子定义了带有一个限定的名为 “choice 的元素。可接受的值是字母 x, y 或 z 中的一个:
1 | <xs:element name="choice"> |
下一个例子定义了带有一个限定的名为 “prodid” 的元素。可接受的值是五个阿拉伯数字的一个序列,且每个数字的范围是 0-9:
1 | <xs:element name="prodid"> |
下面的例子定义了带有一个限定的名为 “letter” 的元素。可接受的值是 a - z 中零个或多个字母:
1 | <xs:element name="letter"> |
下面的例子定义了带有一个限定的名为 “letter” 的元素。可接受的值是一对或多对字母,每对字母由一个小写字母后跟一个大写字母组成。举个例子,”sToP”将会通过这种模式的验证,但是 “Stop”、”STOP” 或者 “stop” 无法通过验证:
1 | <xs:element name="letter"> |
下面的例子定义了带有一个限定的名为 “gender” 的元素。可接受的值是 male 或者 female:
1 | <xs:element name="gender"> |
下面的例子定义了带有一个限定的名为 “password” 的元素。可接受的值是由 8 个字符组成的一行字符,这些字符必须是大写或小写字母 a - z 亦或数字 0 - 9:
1 | <xs:element name="password"> |
如需规定对空白字符(whitespace characters)的处理方式,我们需要使用 whiteSpace 限定。
下面的例子定义了带有一个限定的名为 “address” 的元素。这个 whiteSpace 限定被设置为 “preserve”,这意味着 XML 处理器不会移除任何空白字符:
1 | <xs:element name="address"> |
这个例子也定义了带有一个限定的名为 “address” 的元素。这个 whiteSpace 限定被设置为 “replace”,这意味着 XML 处理器将移除所有空白字符(换行、回车、空格以及制表符):
1 | <xs:element name="address"> |
这个例子也定义了带有一个限定的名为 “address” 的元素。这个 whiteSpace 限定被设置为 “collapse”,这意味着 XML 处理器将移除所有空白字符(换行、回车、空格以及制表符会被替换为空格,开头和结尾的空格会被移除,而多个连续的空格会被缩减为一个单一的空格):
1 | <xs:element name="address"> |
如需限制元素中值的长度,我们需要使用 length、maxLength 以及 minLength 限定。
本例定义了带有一个限定且名为 “password” 的元素。其值必须精确到 8 个字符:
1 | <xs:element name="password"> |
这个例子也定义了带有一个限定的名为 “password” 的元素。其值最小为 5 个字符,最大为 8 个字符:
1 | <xs:element name="password"> |
1 | <xs:attribute name="lang" type="xs:string" default="EN"/> |
1 | <xs:attribute name="lang" type="xs:string" use="required"/> |
1 | #!/usr/bin/perl |
perl uninstall-pandoc.pl
官方链接:http://pandoc.org/installing.html#macos
截图: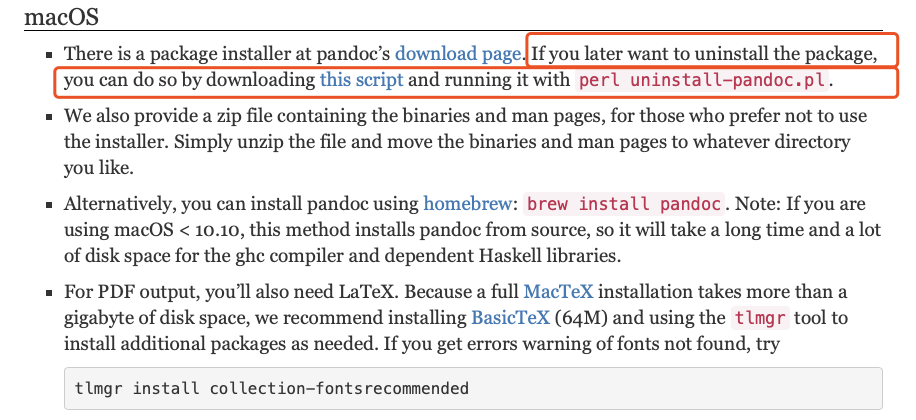
pip install ipython
pip install jupyter
jupyter notebook –generate-config
1 | #: jupyter notebook --generate-config |
jupyter notebook password
1 | #: jupyter notebook password |
cat /home/xm/.jupyter/jupyter_notebook_config.json
1 | #: cat /home/xm/.jupyter/jupyter_notebook_config.json |
vim /home/xm/.jupyter/jupyter_notebook_config.py
1 | #懒得找对应配置项的朋友,直接把这四项配置写到文件开头就可以了 |
df -h
1 | USER_MANE@PC_NAME:~$ df -h |
1 | import threading |
Thread(group=None, target=None, name=None, args=(), kwargs={})
1 | import threading |
1 | #定义字典 |

