通过mac自带的磁盘工具调整虚拟磁盘大小会报错,但是可以通过命令行调整。
如将Hello.dmg调整为7GB:
1 | hdiutil resize -size 7g Hello.dmg |
通过mac自带的磁盘工具调整虚拟磁盘大小会报错,但是可以通过命令行调整。
如将Hello.dmg调整为7GB:
1 | hdiutil resize -size 7g Hello.dmg |
打开terminal运行以下指令:
1 | launchctl stop com.apple.CalendarAgent |
将YOURNOTEBOOKNAME替换为需要转换的文件名称,运行以下命令即可
1 | jupyter nbconvert --to script YOURNOTEBOOKNAME.ipynb |
如果使用了anaconda环境,且未将其设置为默认环境的话,可以在jupyter命令前补充安装路径。
以安装路径为“~/opt/anaconda3”为例:
1 | ~/opt/anaconda3/bin/jupyter nbconvert --to script YOURNOTEBOOKNAME.ipynb |
量子计算的基本单位是量子比特,量子比特用向量 $|\psi\rangle$ (狄拉克Dirac符号)来描述。
基态: $|g\rangle=|1\rangle=\left[ \begin{matrix} 0 \\ 1 \end{matrix} \right]$
激发态: $∣e\rangle=|0\rangle=\left[ \begin{matrix} 1 \\ 0 \end{matrix} \right]$
在量子理论中,描述量子态的向量称为态矢,态矢分为左矢和右矢。相同描述对象的左矢和右矢互为转置共轭。
pyqpanda中,dagger()函数可用于对逻辑门进行转置共轭操作
右失(ket): $|\psi\rangle=\left[ \begin{matrix} c_1 & c_2 & \cdots & c_n \end{matrix} \right]^T=\left[ \begin{matrix} c_1 \\ c_2 \\ \vdots \\ c_n \end{matrix} \right]$
左失(bra): $\langle\psi|=\left[ \begin{matrix} c_1^* & c_2^* & \cdots & c_n^* \end{matrix} \right]$
并不是任意的二维向量都能用来描述一个qubit的状态,描述量子态的向量的模长必须为1,所谓向量的模长定义如下:
$M(\alpha) = \sqrt{|a_{1}|^{2} + |a_{2}|^{2} + … + |a_{n}|^{2}}$
量子比特各维度的平方为量子处于该状态的概率。
对于一组向量 $|u_1\rangle, |u_2\rangle, \cdots, |u_n\rangle$ 张成(spanning)的 $n$ 维空间 $C^n$ ,空间中的任意向量可以表示为: $|v\rangle=\sum_i x_i u_i$ ,这个集合 ${|u_1\rangle, |u_2\rangle, \cdots, |u_n\rangle}$ 就称为 $C^n$ 的基(basis)。
在 $C^n$ 上的内积表示为(注意 $a_i^*$ 为 $a_i$ 的共轭!):
$\langle \alpha | \beta \rangle = (|\alpha\rangle, |\beta\rangle) = ((a_1, \cdots ,a_n),(b_1, \cdots, b_n)) = \sum_{i=1}^{n}a_i^*b_i$
可以看做 $\langle \alpha|$ 共轭转置后得到的 $1 \times n$ 的矩阵与 $| \beta \rangle$ 构成的 $n \times 1$ 的矩阵的积,内积的结果是一个值。
外积 $| \alpha \rangle \langle \beta |$ 可以看做 $\langle \alpha|$ 的 $n \times 1$ 的矩阵与 $| \beta \rangle$ 共轭转置后构成的 $1 \times n$ 的矩阵的积,外积的结果是一个矩阵!
向量 $|\alpha\rangle$ 、 $|\beta\rangle$ 在 $C^n$ 、 $C^m$ 中的张量积为 $C^{n\times m}$ 中的向量: $|\alpha\rangle\otimes|\beta\rangle=|\alpha\rangle|\beta\rangle=|\alpha\beta\rangle$ ,计算方法为:
$\left[ \begin{matrix} a_1 \\ a_2 \end{matrix} \right]\times\left[ \begin{matrix} b_1 \\ b_2 \end{matrix} \right] = \left[ \begin{matrix} a_1 b_1 \\ a_1 b_2 \\ a_2 b_1 \\ a_2 b_2 \end{matrix} \right]$
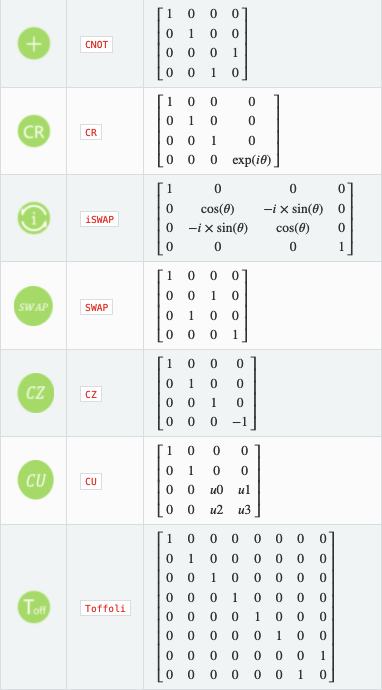
当单比特量子逻辑门作用于量子比特时,为门在前比特在后进行矩阵相乘,进而改变比特状态。
其中:

当多比特量子逻辑门作用于多个量子比特时,为门在前,多个量子比特的张量积在后,进行矩阵相乘。
在关系图中,每条实线都描述一个量子比特,更常见地是描述一个量子比特寄存器。按照约定,最上面那根线是量子比特寄存器0,其余的按顺序标记。根据描述,上面的示例线路作用于两个量子比特(或等效为作用于两个寄存器,每个寄存器由一个量子比特组成)。作用于一个或多个量子比特寄存器的门用一个框表示。例如,符号
量子门按时间顺序排列,最左侧的门是应用于量子比特的第一个门。 也就是说,如果你将线描述为包含量子态,那么这些线将按图中从左到右的顺序带着量子态通过每个门。 也就是说
是酉矩阵 $CBA$ 。矩阵乘法遵守相反的约定,即最先应用最右侧的矩阵。不过,在量子线路图中,最先应用的是最左侧的门。这种差异有时可能会导致混淆,因此有必要记下线性代数表示法和量子关系图之间的这一明显差异。
多量子比特量子线路图中内置的另一个构造是控制。量子单个受控门表示为 $\Lambda(G)$ ,其中单个量子比特的值控制 $G$ 的应用。要理解该受控门的操作,可查看下面的示例,它是一个乘积态输入 $\Lambda(G)(\alpha|0\rangle+\beta|1\rangle)|\psi\rangle=\alpha|0\rangle|\psi\rangle+\alpha|1\rangle G|\psi\rangle$ 。也就是说,当且仅当控制量子比特采用值时,该受控门才对包含 $\phi$ 的寄存器应用 $G$ 。通常,我们在线路图中将这种受控操作描述为
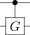
在这里,黑色圆圈表示门受控的量子位,垂直线表示当控制量子比特采用值1时应用的酉操作。对于 $G=X$ 和 $G=Z$ 的特殊情况,我们引入了以下表示法来描述门的受控版本(请注意,受控 $X$ 门是 $CNOT$ 门):
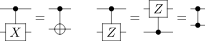
在线路图中直观呈现的剩余操作是测量。测量采用量子比特寄存器、对其进行测量,然后以经典信息的形式输出结果。测量操作由计量符号表示,它始终将输入看做是一个量子比特寄存器(表示为实线),将输出看做是经典信息(表示为双线)。具体来说,这种子线路如下所示:

References:
https://blog.csdn.net/si_ying/article/details/108303988
https://pyqpanda-toturial.readthedocs.io/
https://docs.microsoft.com/zh-cn/azure/quantum/concepts-circuits
https://www.cxyzjd.com/article/qq_43391414/118766778
https://swardsman.github.io/learning-q-sharp/
冠词是置于名词前并限定名词的意义的虚词,分为定冠词和不定冠词,实际使用中,还会出现零冠词,共三种情况。
用于表示特指。
但是,by weight(按重量)习惯上不用冠词。如:Bananas are usually sold by weight. 香蕉通常按重量卖。
用于表示泛指。
用于表示泛指。
泡利算符是一组三个2×2的幺正厄米复矩阵,又称酉矩阵。我们一般都以希腊字母 $\sigma$ 来表示。 在 QPanda 中我们称它们为X门,Y门,Z门。它们对应的矩阵形式如下。
X:
$\sigma_x = \left[\begin{matrix}
0 & 1 \\
1 & 0
\end{matrix}\right]$
Y:
$\sigma_y = \left[\begin{matrix}
0 & -i \\
i & 0
\end{matrix}\right]$
Z:
$\sigma_z = \left[\begin{matrix}
1 & 0 \\
0 & -1
\end{matrix}\right]$
每个抛离矩阵有两个特征值,+1和-1,其对应的归一化特征向量为:
$\psi_{x+}=\frac{1}{\sqrt{2}}\left[\begin{matrix}
1 \\
1
\end{matrix}\right]$
$\psi_{x-}=\frac{1}{\sqrt{2}}\left[\begin{matrix}
1 \\
-1
\end{matrix}\right]$
$\psi_{y+}=\frac{1}{\sqrt{2}}\left[\begin{matrix}
1 \\
i
\end{matrix}\right]$
$\psi_{y-}=\frac{1}{\sqrt{2}}\left[\begin{matrix}
1 \\
-i
\end{matrix}\right]$
$\psi_{z+}=\left[\begin{matrix}
1 \\
0
\end{matrix}\right]$
$\psi_{z-}=\left[\begin{matrix}
0 \\
1
\end{matrix}\right]$
1 | from pyqpanda import * |
其中PauliOperator p2(“Z0 Z1”, 2)表示的是 $2\sigma_{0}^{z} \otimes \sigma_{1}^{z}$ ,这里的 $\otimes$ 表示克罗内克积(Kronecker product),也称作张量积、张乘。
1 | from pyqpanda import * |

reference:
https://pyqpanda-toturial.readthedocs.io/zh/latest/PauliOperator.html
https://www.bilibili.com/video/BV124411b7bd?p=3
SAT问题(Boolean Satisfiability Problem)是判断一个以合取范式形式给出的逻辑命题公式是否存在一个真值指派,使得公式为真。
SAT 可满足问题是第一个被证明的NP问题(就是能在多项式时间验证答案正确与否的问题)
解决方法:
P问题:在多项式时间内能够求解,是一类可以通过确定性图灵机在多项式时间(Polynomial time)内解决的问题集合。
NP问题:在多项式时间里能够验证是否有解,可以通过非确定性图灵机(Non-deterministic Turing Machine)在多项式时间(Polynomial time)内解决的决策问题集合。
NOTE:P是NP的子集,也就是说任何可以被图灵机在多项式时间内解决的问题都可以被非确定性的图灵机解决。
如果一个决策问题 L 是 NP-complete的,那么L具备以下两个性质:
而NP-hard只需要具备NP-complete的第二个性质,因此NP-complete是NP-hard的子集。
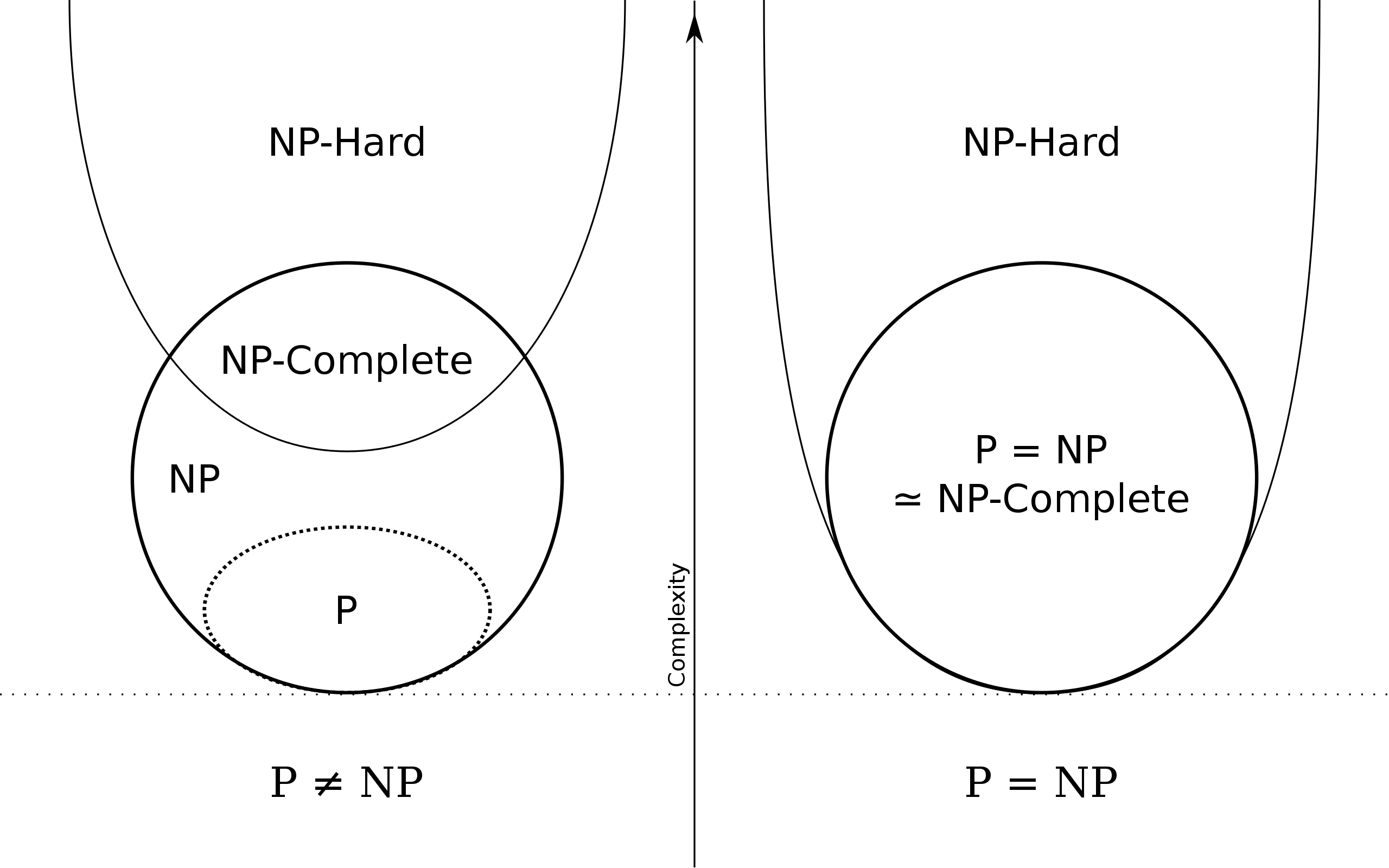
研究中遇到的大部分问题都是NPC问题,选择的方法可以视问题的输入规模而定:
reference:
https://www.cnblogs.com/sancyun/p/4250360.html
https://baike.baidu.com/item/布尔可满足性问题/4715567?fr=aladdin
https://blog.csdn.net/zhushiq1234/article/details/79484280
https://en.wikipedia.org/wiki/NP_(complexity)
