# 可以用list函数取出子元素的list children = list(root) print(root) print(children)
<Element root at 0x107b03888>
[<Element child0 at 0x107b034c8>, <Element child1 at 0x107b03448>, <Element child2 at 0x107b038c8>, <Element child3 at 0x107b03908>]
1 2 3 4 5 6 7
# 通过长度检查element是否为叶子节点 if len(root): print('root has children') if len(child1): print('child1 has children') else: print('child1 has no child')
# 可以通过在iter中添加参数,来过滤输出的tag for element in root.iter("child"): print("%s - %s" % (element.tag, element.text)) for element in root.iter("another", "child"): print("%s - %s" % (element.tag, element.text))
for event in events: print('event: %s - tag: %s' % (event[0], event[1])) for attr, value in event[2].items(): print(' * %s = %s' % (attr, value))
1
event: start - tag: root
* test = true
/Users/imonce/anaconda/lib/python3.6/site-packages/ipykernel_launcher.py:15: DeprecationWarning: inspect.getargspec() is deprecated, use inspect.signature() or inspect.getfullargspec()
from ipykernel import kernelapp as app
# E-factory:提供一种简单紧凑的语法来生成XML和HTML from lxml.builder import E
defCLASS(*args):# class 是python中的保留字,无法直接当做属性名 return {"class":' '.join(args)}
html = page = ( E.html( # create an Element called "html" E.head( E.title("This is a sample document") ), E.body( E.h1("Hello!", CLASS("title")), E.p("This is a paragraph with ", E.b("bold"), " text in it!"), E.p("This is another paragraph, with a", "\n ", E.a("link", href="http://www.python.org"), "."), E.p("Here are some reserved characters: <spam&egg>."), etree.XML("<p>And finally an embedded XHTML fragment.</p>"), ) ) )
<html>
<head>
<title>This is a sample document</title>
</head>
<body>
<h1 class="title">Hello!</h1>
<p>This is a paragraph with <b>bold</b> text in it!</p>
<p>This is another paragraph, with a
<a href="http://www.python.org">link</a>.</p>
<p>Here are some reserved characters: <spam&egg>.</p>
<p>And finally an embedded XHTML fragment.</p>
</body>
</html>
# 此外还有一种基于属性的方法 from lxml.builder import ElementMaker # lxml only !
E = ElementMaker(namespace="http://my.de/fault/namespace", nsmap={'p' : "http://my.de/fault/namespace"})
DOC = E.doc TITLE = E.title SECTION = E.section PAR = E.par
my_doc = DOC( TITLE("The dog and the hog"), SECTION( TITLE("The dog", tType='title'), PAR("Once upon a time, ..."), PAR("And then ...") ), SECTION( TITLE("The hog"), PAR("Sooner or later ...") ) )
<p:doc xmlns:p="http://my.de/fault/namespace">
<p:title>The dog and the hog</p:title>
<p:section>
<p:title tType="title">The dog</p:title>
<p:par>Once upon a time, ...</p:par>
<p:par>And then ...</p:par>
</p:section>
<p:section>
<p:title>The hog</p:title>
<p:par>Sooner or later ...</p:par>
</p:section>
</p:doc>
from __future__ import absolute_import from __future__ import division from __future__ import print_function
from sklearn.manifold import TSNE import matplotlib.pyplot as plt
import collections import math import os import random import zipfile
import numpy as np from six.moves import urllib from six.moves import xrange import tensorflow as tf
classBasicPatternEmbedding: def__init__(self): self.url = 'http://mattmahoney.net/dc/' self.data_index = 0 self.vocabulary_size = 5000 self.batch_size = 128 self.embedding_size = 128# Dimension of the embedding vector. self.skip_window = 1# How many words to consider left and right. self.num_skips = 2# How many times to reuse an input to generate a label.
# We pick a random validation set to sample nearest neighbors. Here we limit the # validation samples to the words that have a low numeric ID, which by # construction are also the most frequent. self.valid_size = 16# Random set of words to evaluate similarity on. self.valid_window = 100# Only pick dev samples in the head of the distribution. # choose 16 numbers from 0 to 99 randomly self.valid_examples = np.random.choice(self.valid_window, self.valid_size, replace=False) self.num_sampled = 64# Number of negative examples to sample. self.num_steps = 10001 self.final_embedding = None self.graph = tf.Graph() # download and verify the dataset file defmaybe_download(self, filename, expected_bytes): # If the dataset file is not under the current path, download it directly ifnot os.path.exists(filename): filename, _ = urllib.request.urlretrieve(self.url + filename, filename) # get dataset file infomationn statinfo = os.stat(filename) # verify file size if statinfo.st_size == expected_bytes: print('Found and verified', filename) else: print(statinfo.st_size) raise Exception( 'Failed to verify ' + filename + '. Can you get to it with a browser?') return filename # read the data from zip into a list of strings defread_data(self, filename): with zipfile.ZipFile(filename) as f: # separate by default separators, that is, all null characters, including spaces, newlines (\n), tabs (\t), etc. data = tf.compat.as_str(f.read(f.namelist()[0])).split() return data # process raw inputs into a dataset defbuild_dataset(self, words): # add unknown words into count list count = [['UNK', -1]] # count the words list and add the pairs (word_name, number) into count list count.extend(collections.Counter(words).most_common(self.vocabulary_size - 1)) dictionary = dict() # create a dictionary of the words with serial number for word, _ in count: dictionary[word] = len(dictionary) data = list() unk_count = 0 # convert the word list into a number list, 0 for unknown words for word in words: if word in dictionary: index = dictionary[word] else: index = 0 unk_count += 1 data.append(index) # update the number of UNK count[0][1] = unk_count # generate a new dictionary by exchanging key and value reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return data, count, dictionary, reversed_dictionary # function to generate a training batch for the skip-gram model defgenerate_batch(self, data): # make sure the data length is OK assert self.batch_size % self.num_skips == 0 assert self.num_skips <= 2 * self.skip_window
batch = np.ndarray(shape=(self.batch_size), dtype=np.int32) labels = np.ndarray(shape=(self.batch_size, 1), dtype=np.int32) span = 2 * self.skip_window + 1# [ skip_window target skip_window ] # create a new double-ended queue to store the buffer buffer = collections.deque(maxlen=span) # data_index indicates the end point of the current window if self.data_index + span > len(data): data_index = 0 buffer.extend(data[self.data_index:self.data_index + span]) self.data_index += span for i in range(self.batch_size // self.num_skips): target = self.skip_window # target label at the center of the buffer targets_to_avoid = [self.skip_window] # sample num_skips batches and labels, optimizable for j in range(self.num_skips): while target in targets_to_avoid: target = random.randint(0, span - 1) # avoid sampling to the same target targets_to_avoid.append(target) # each batch item stands for input batch[i * self.num_skips + j] = buffer[self.skip_window] # each label item stands for ground truth labels[i * self.num_skips + j, 0] = buffer[target] if self.data_index == len(data): buffer[:] = data[:span] self.data_index = span else: buffer.append(data[self.data_index]) self.data_index += 1 # Backtrack a little bit to avoid skipping words in the end of a batch self.data_index = self.data_index - span return batch, labels deftrain(self, data, reverse_dictionary): with self.graph.as_default(): train_inputs = tf.placeholder(tf.int32, shape=[self.batch_size]) train_labels = tf.placeholder(tf.int32, shape=[self.batch_size, 1]) valid_dataset = tf.constant(self.valid_examples, dtype=tf.int32)
# Ops and variables pinned to the CPU with tf.device('/cpu:0'): # Look up embeddings for inputs. embeddings = tf.Variable(tf.random_uniform([self.vocabulary_size, self.embedding_size], -1.0, 1.0)) # according to embeddings, the 128-dimensional vector corresponding to the input word(train inputs) was extracted embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Construct the variables for the NCE loss nce_weights = tf.Variable(tf.truncated_normal([self.vocabulary_size, self.embedding_size], stddev=1.0 / math.sqrt(self.embedding_size))) nce_biases = tf.Variable(tf.zeros([self.vocabulary_size])) # Compute the average NCE loss for the batch. # tf.nce_loss automatically draws a new sample of the negative labels each # time we evaluate the loss. loss = tf.reduce_mean( tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed, num_sampled=self.num_sampled, num_classes=self.vocabulary_size)) # Construct the SGD optimizer using a learning rate of 1.0. optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
# Compute the cosine similarity between minibatch examples and all embeddings. norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset) similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
# Add variable initializer. init = tf.global_variables_initializer() with tf.Session(graph = self.graph) as session: init.run() average_loss = 0 for step in xrange(self.num_steps): batch_inputs, batch_labels = self.generate_batch(data) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}
# we perform one update step by evaluating the optimizer op (including it # in the list of returned values for session.run() _, loss_val = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += loss_val if step % 2000 == 0: if step > 0: average_loss /= 2000 # the average loss is an estimate of the loss over the last 2000 batches. print('Average loss at step ', step, ': ', average_loss) average_loss = 0 # output the most similar eight words to the screen if step % 10000 == 0: sim = similarity.eval() for i in xrange(self.valid_size): valid_word = reverse_dictionary[self.valid_examples[i]] top_k = 8# number of nearest neighbors nearest = (-sim[i, :]).argsort()[1:top_k + 1] log_str = 'Nearest to %s:' % valid_word for k in xrange(top_k): close_word = reverse_dictionary[nearest[k]] log_str = '%s %s,' % (log_str, close_word) print(log_str) self.final_embeddings = normalized_embeddings.eval() # visualize the embeddings defplot_with_labels(self, low_dim_embs, labels, filename='tsne.png'): assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings' plt.figure(figsize=(18, 18)) # in inches for i, label in enumerate(labels): x, y = low_dim_embs[i, :] plt.scatter(x, y) plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.show() #plt.savefig(filename)
# Signature: tf.nn.embedding_lookup(params, ids, partition_strategy='mod', name=None, validate_indices=True, max_norm=None) # Docstring: # Looks up `ids` in a list of embedding tensors.
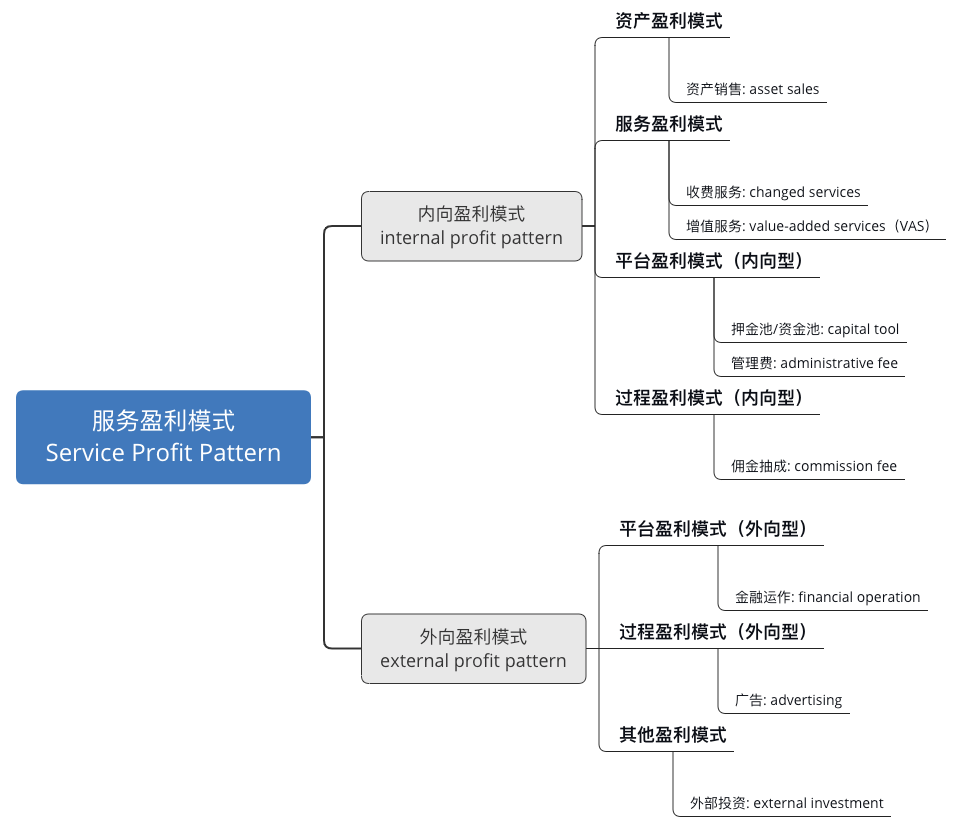
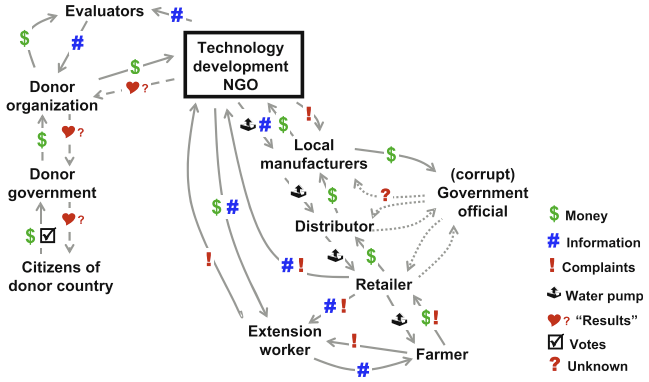
Customer Value Chain Analysis (CVCA) is an original methodological tool that enables design teams in the product definition phase to comprehensively identify pertinent stakeholders, their relationships with each other, and their role in the product’s life cycle.
method
CVCA Step 1: Determine the business model for the vending machine.
CVCA Step 2: Delineate pertinent parties involved with the vending machine’s life cycle.
CVCA Step 3: Determine how the vending machine’s customers are related to each other.
CVCA Step 4: Identify the value propositions of the vending machine’s customers and define the flows between them.
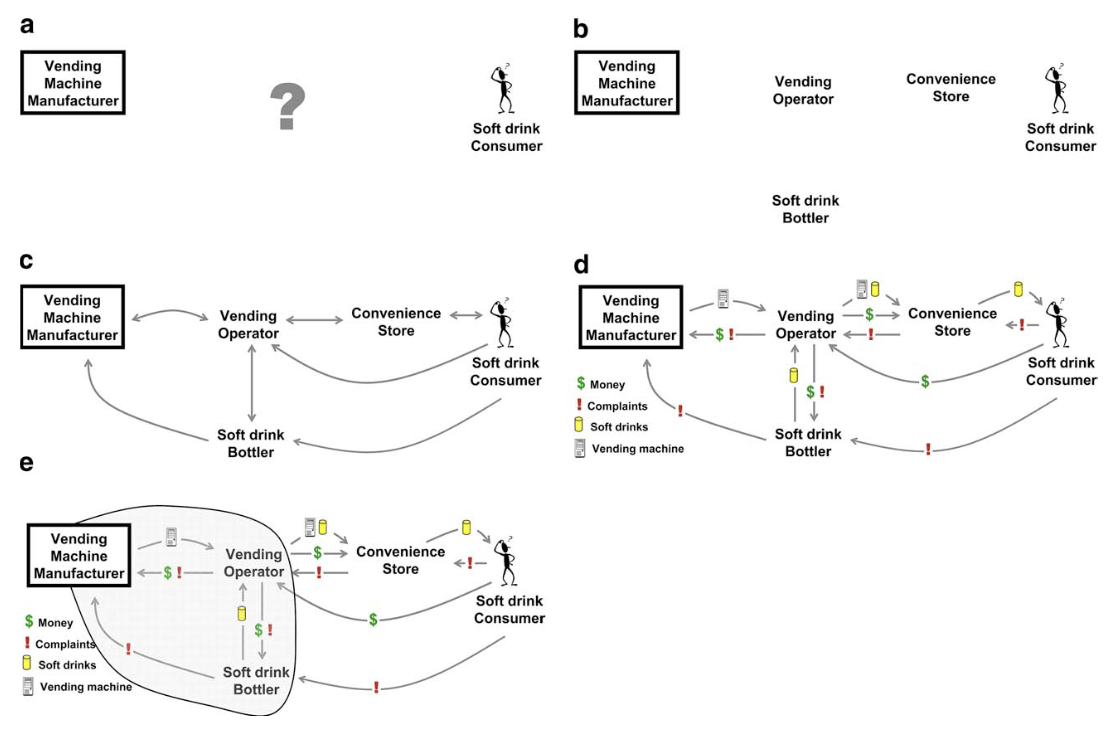
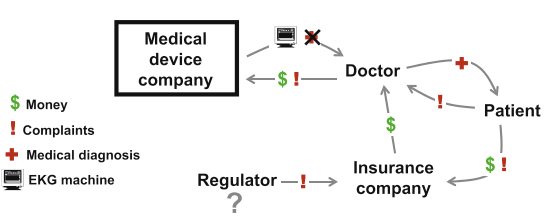
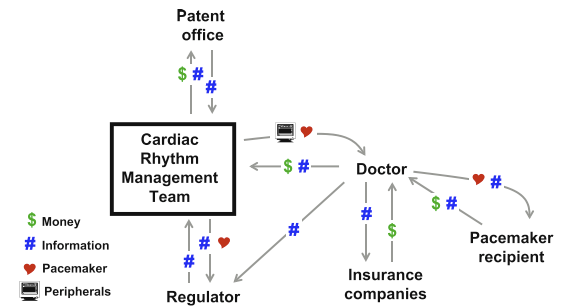
CVCA Step 5: Analyze the Customer Chain to determine the vending machine’s critical customers and their value propositions. The vending operator and the soft drink bottler (circled) were determined to be the critical customers to the vending machine manufacturer.
This paper presents three interrelated frameworks as a first attempt to define the fundamentals of service systems.
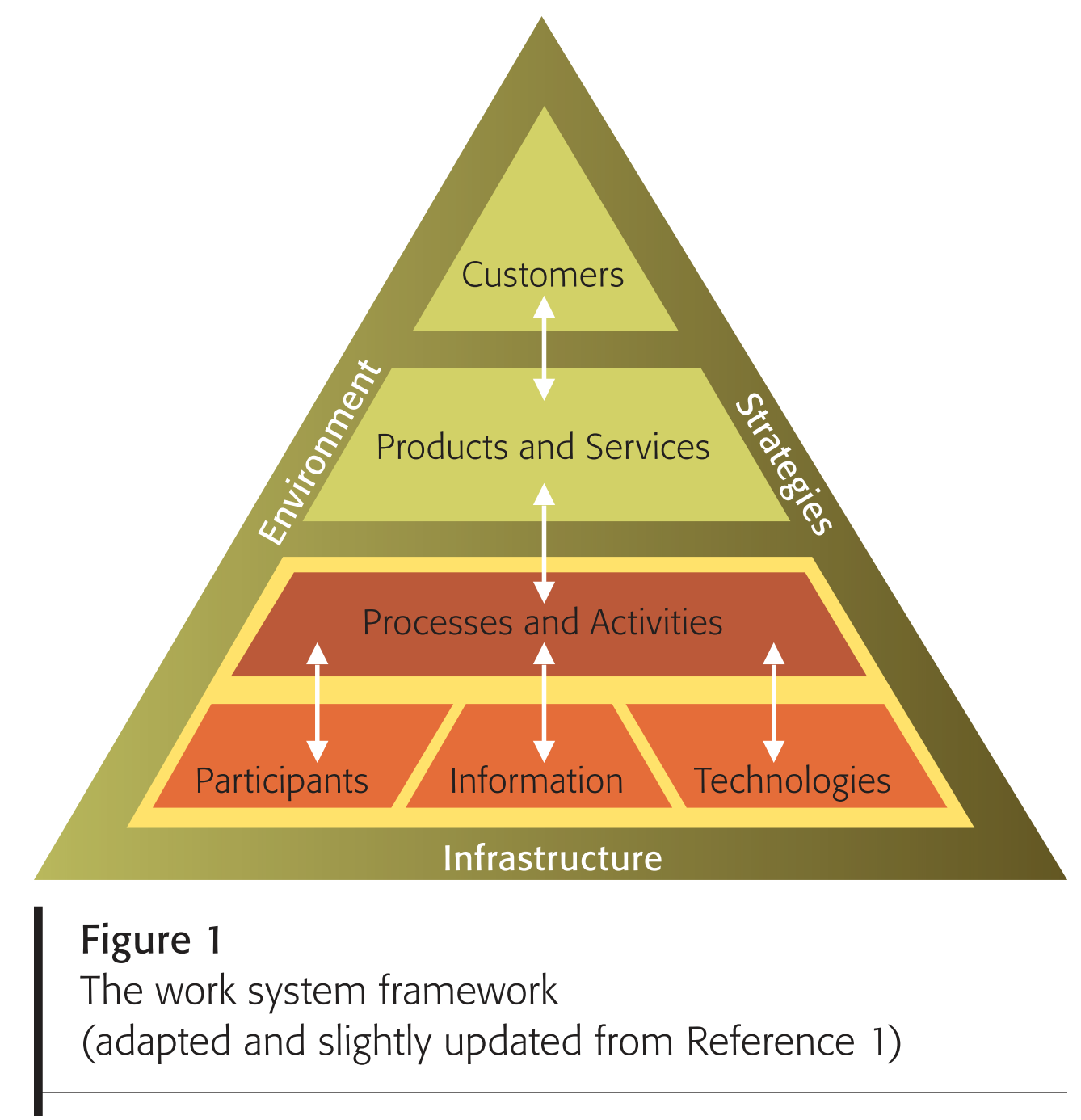
The work system framework uses nine basic elements to provide a system-oriented view of any system that performs work within or across organizations. Service systems are work systems.
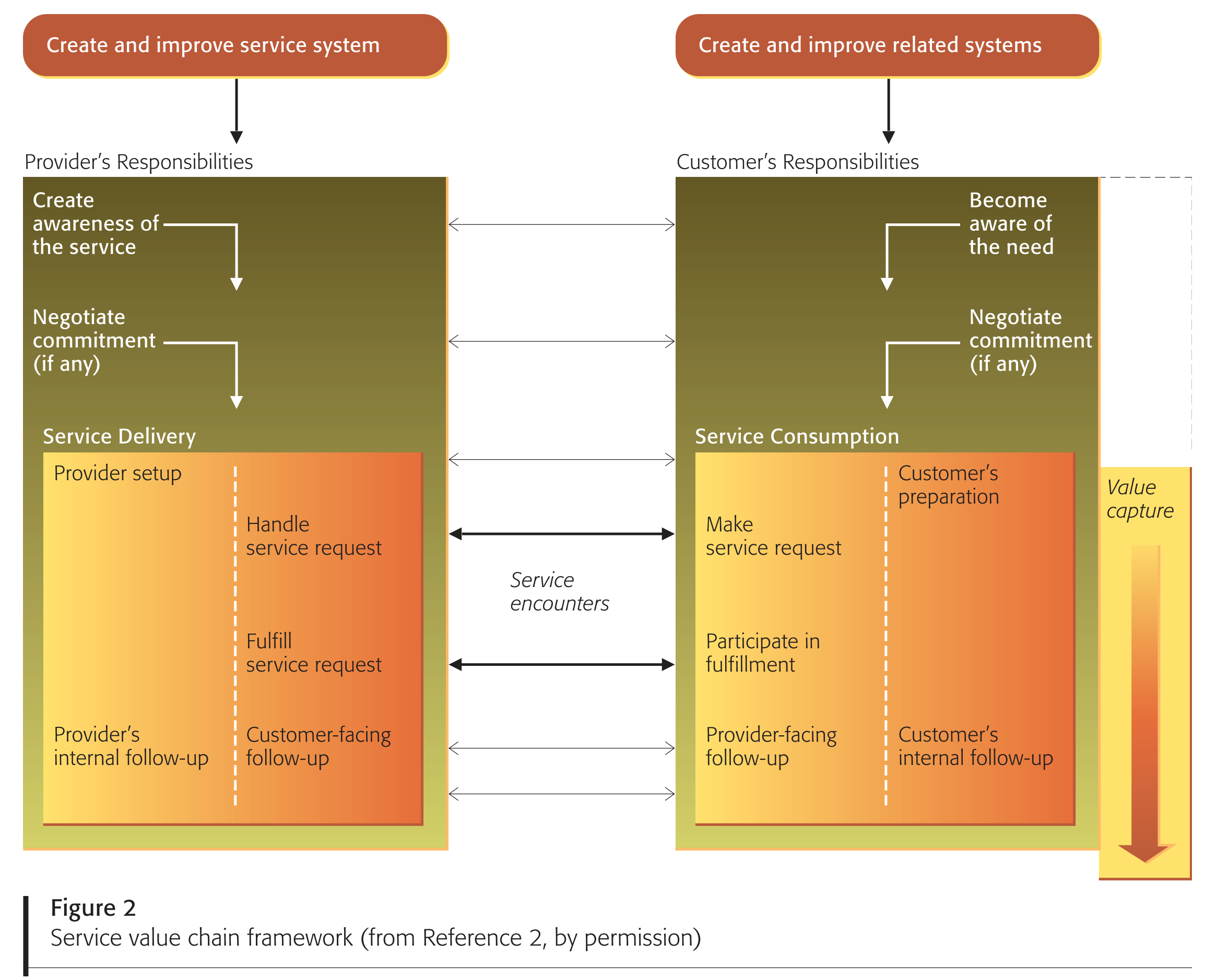
The service value chain framework augments the work system framework by introducing functions that are associated specifically with services. It presents a two-sided view of service processes based on the common observation that services are typically coproduced by service providers and customers.
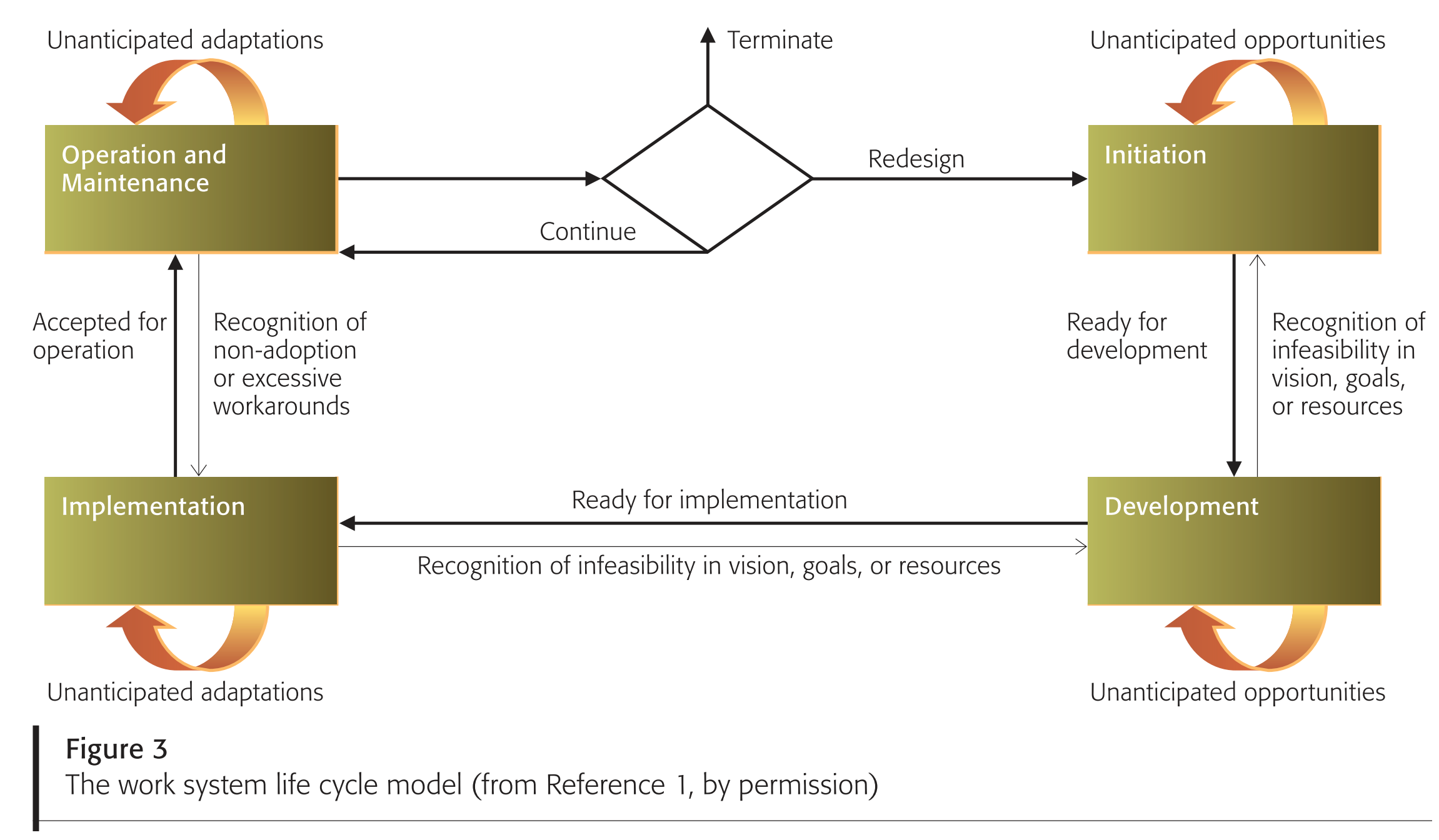
The work system life cycle model looks at how work systems (including service systems) change and evolve over time. It treats the life cycle of a system as a set of iterations involving planned and unplanned change.
This paper uses two examples, one largely manual and one highly automated, to illustrate the potential usefulness of the three frameworks, which can be applied together to describe, analyze, and study how service systems are created, how they operate, and how they evolve through a combination of planned and unplanned change.
A precise and unambiguous description of the meaning of a mathematical term. It characterizes the meaning of a word by giving all the properties and only those properties that must be true.
A mathematical statement that is proved using rigorous mathematical reasoning. In a mathematical paper, the term theorem is often reserved for the most important results.
用严格的数学推理证明的数学陈述。在数学论文中,术语定理通常是为最重要的结果而保留的。
Lemma(引理)
A minor result whose sole purpose is to help in proving a theorem. It is a stepping stone on the path to proving a theorem. Very occasionally lemmas can take on a life of their own.
唯一目的是帮助证明定理的小结果。这是证明一个定理之路的踏脚石。极少情况下引理可以独立存在。
Corollary(推论)
A result in which the (usually short) proof relies heavily on a given theorem (we often say that “this is a corollary of Theorem A”).
证明(通常是简短的)很大程度上依赖于一个给定定理的结果(我们经常说“这是定理A的一个推论”)。
Proposition(命题)
A proved and often interesting result, but generally less important than a theorem.
一个被证明的,通常很有趣的结果,但一般没有定理重要。
Conjecture(推测,猜想)
A statement that is unproved, but is believed to be true.
Claim(断言)
An assertion that is then proved. It is often used like an informal lemma.
未经证实但被认为是真实的陈述。
Axiom/Postulate(公理/假定)
A statement that is assumed to be true without proof. These are the basic building blocks from which all theorems are proved.
没有证明,且假设为真的陈述。这些是证明所有定理的基本构造块。
Identity(恒等式)
A mathematical expression giving the equality of two (often variable) quantities.
两个(通常是可变的)量相等的数学表达式。
Paradox(悖论)
A statement that can be shown, using a given set of axioms and de nitions, to be both true and false. Paradoxes are often used to show the inconsistencies in an awed theory. The term paradox is often used informally to describe a surprising or counterintuitive result that follows from a given set of rules.
构造性的证明与计算机程序概念有密切关系:为构造地证明命题 $(\forall x \in A)(\exists y \in B)P(x,y)$ ,必须要给出函数f,使f应用于A中元素a时,产生B中元素b,使P(a,b)满足。如果P(a,b)描述了一个规约,则证明该命题的函数f就是满足该规约的一个程序。所以,可以吧构造证明本身看成是一个计算机程序,程序的计算过程与证明的规范化对应。正因为构造性证明的这一计算内容,可把类型轮用作一种程序设计语言,而且,由于程序是从他的说明的证明中得到的,类型轮还可以用作程序设计逻辑。





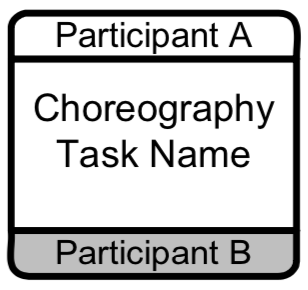
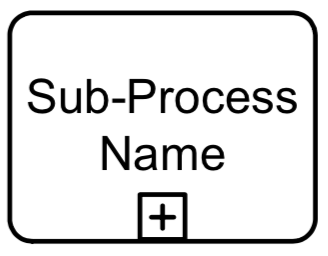 Expanded Sub-Process
Expanded Sub-Process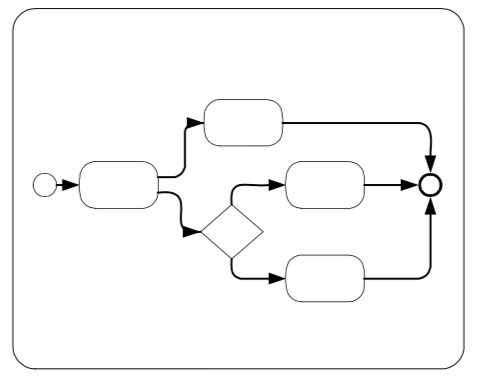 Collapsed Sub- Choreography
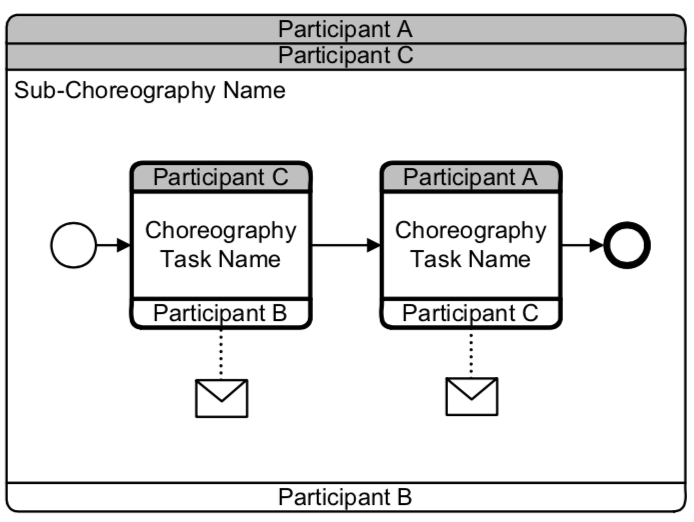
Collapsed Sub- Choreography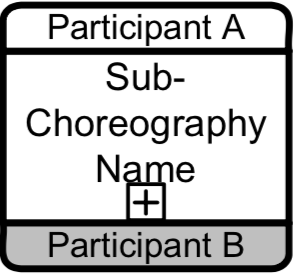 Expanded Sub-Choreography
Expanded Sub-Choreography