1、知识图谱系统的关键特性有哪些?
1.当然是可视化展示,知识图谱的魅力之一就是让人直观的看到多实体之间的关系,能用图标示的就不要哔哔
2.多种服务提供方式,有些服务使用方,不需要图,那么可能通过api或者批量文件的方式比较合适。所以从系统建设角度来看,最好能提供多样的服务对接方式,满足前端服务使用方的不同需要,发挥系统价值,是值得考虑的地方。
3.查询速度,在用户进行图操作,例如实体查询、关系推演扩展时,系统响应时间应该较低,避免大并发情况下用户体验的降低。
数据建模、批量时间相对来说,外界感知不到,因此不那么重要。
2、知识图谱适用场景有哪些?
主要涉及关系分析的场景,利用账户、自然人或者资金交易形成的关系来判定结果是否可用时,比如担保圈、分析实际控制人、实际受益人、识别冒名贷款。而且通常,数据分析的深度在3度到5度,才能体现出优势。
分析深度小于3度,与传统关系型数据库没有太大差别,大于5度有可能引入较多的噪音数据。当然不排除某些场景下分析5度以上数据的可能性。
3、有没有业务场景是只能用知识图谱实现的?而其他技术方法无法实现?
从技术角度考虑,应该没有,有的是效率孰高孰低、开发成本孰高孰低。
4、知识图谱应用时会面临哪些主要的困难,如何解决?
主要是确认需求,一方面是适不适合用知识图谱这个工具,另一方面做好与其他系统的对接工作,如何能将知识图谱这个服务以简便快捷的方式输出给其他系统。前者可以和多方面行内外专家交流,后者主要还是要与业务部门进行沟通,确认业务部门的期望,技术实现大多时候不是难点,难的是如何满足欲壑难填的需求。
5、知识图谱系统的建设核心是什么?该如何选型?
建设核心是图数据的存储和分析方法。不同的核心,外围使用的方法也不同。
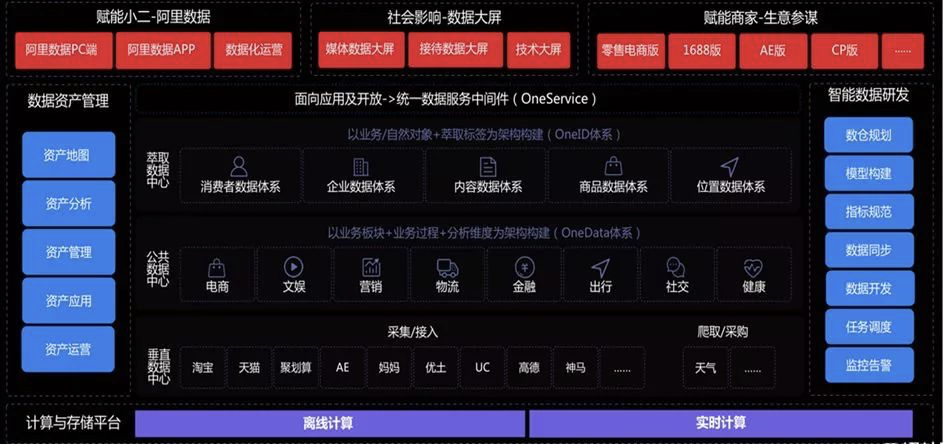
以titan为例,它是集成在hadoop上的。数据的分析加工主要在使用sparksql和graphx,结果会存放在titan中,数量较多的明细流水会放在hbase中,常用的查询关键字,姓名、手机号码等会放在elasticsearch中,三者通过key相互关联。
如果换一种图数据库,比如neo4j,整个外围都会跟着调整。所以图数据库的选型不能进场图数据本身考虑,而应该结合整体规划,建设成本,多系统间的关联关系层面进行统筹考虑,甚至可能会为了大局牺牲一些效率。
6、图形数据库应该怎么选型?选的时候需要考虑哪些问题?
从系统自身考虑的话,包括高可靠性,读写效率、扩展性,与其他系统相同。
除此之外,还应该从整体规划和这个系统所处的位置进行考虑,为了满足整体规划,牺牲一些性能或者成本也是必要的。比如为了避免海量数据的多系统存储分析,就选用了以hadoop为基础的图数据库,这样所有的数据只需一份,可以供平台上的多个子系统进行使用。
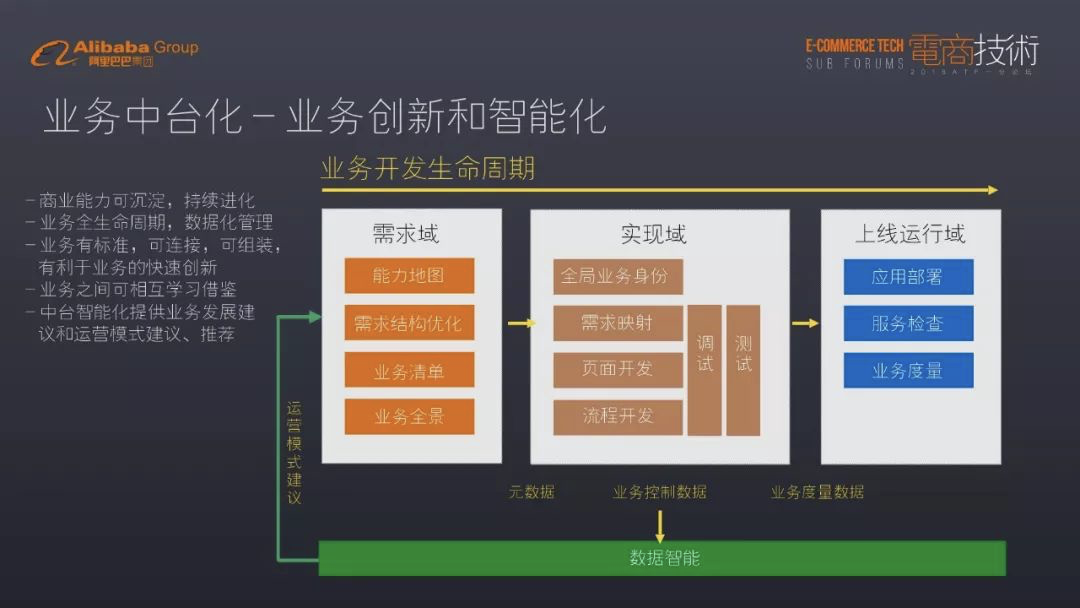
7、为满足关键特性系统的架构或组件选择是怎样的?(主要针对hadoop架构)
1.可视化需要开发一个专门的知识图谱展示界面,将知识图谱中的实体、关系属性等以美观已操作的方式展示出来,因为颜值即正义。可以借用当前比较流行的bootstrap等前端开发语言。
2.为满足快速查询,可以将部分索引关键字放在索引es中,索引命中后在使用key去titian中查询。
3.多种服务方式,需要从设计时就进行考虑,至少满足三种api、可视化界面、批量文件。批量文件主要从hive中进行导出,而api接口则需要开发一个服务层,将所有图数据库的命令行操作转换为对应的api接口,轻量级的开发一个java服务放在tomcat中,有条件的可以使用微服务框架。
8、知识图谱的建设都有哪些重要的环节,需要注意什么?
从自身项目实施来看,有三个地方:
1.建模时多系统数据的融合,比如客户的信息存在多个系统中,核心、信贷、理财等,因为系统建设时间不一、多次升级等问题,导致数据不一致,数据质量较差,这样就需要花费很大精力去处理数据质量问题,还可能导致程序返工。
2.模型开发过中,选择哪些业务场景也很重要,知识图谱不是万金油,有些场景比较费力。应该选择那些跟关联关系分析相关的,有明确结果,业务人员能够明确正确与否的应用场景,便于展示这个工具的优越性。
3.交付前的测试也很重要。因为知识图谱基本上都是需要融合各个业务系统的数据,涉及面较广。因此要给测试过程留够时间,便于测试人员发现一些数据处理上的遗漏。
9、知识图谱与智能客服如何对接?
主要是通过API接口,在接入的同时系统自动调出客户当前的资产负债状况,最近的交易明细,购买产品的状况。在提问的时候,通过nlp系统解析问题中的关键字,识别询问的实体、关系等,找到关联的问题,引导客户按照提问已有的问题。使用知识图谱的好处在于,可以快速的查询出客户周边的所有数据。如果使用传统关系型数据库,则需要按照业务种类,逐个表进行查询,分模块展示。在图谱中则可以一起展示出来,因为是从客户出发按照关联关系进行查询的,并且可以用一张图进行直观的展示。
10、部署时需要满足怎样的性能要求,qps或tps?如果建设面向外部客户的大规模知识图谱,有哪些可以优化的方向?
性能的需求应该是与业务场景强相关的,如果是面向外部客户那就要考虑扩容节点提升整体性能,明细数据可以从hbase迁移到es中,加快查询速度,限制部分查询内容或者只能查看经过分析的子图。
对于行内系统,从数据安全角度来看,只有少部分人能看到所有数据,绝大多数人只能看到部分数据,而且应该是具有特定业务含义的数据,比如某个预警模型的结果。在这种情况下,权限范围内的数据量就很小了,那么在查询的过程中,效率也会相应提升,不会全表扫描。
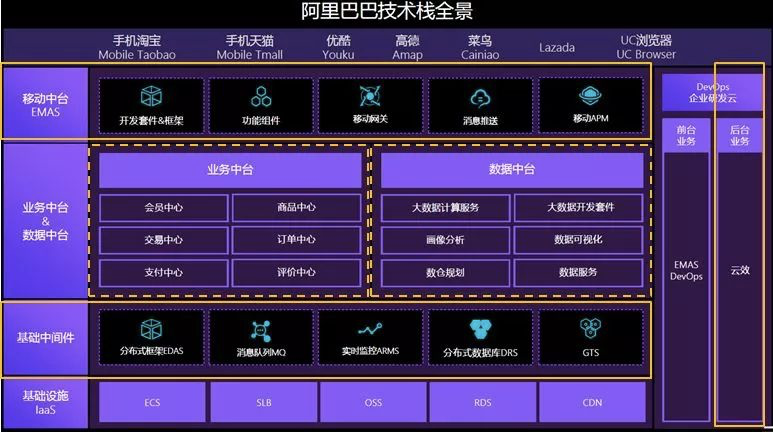
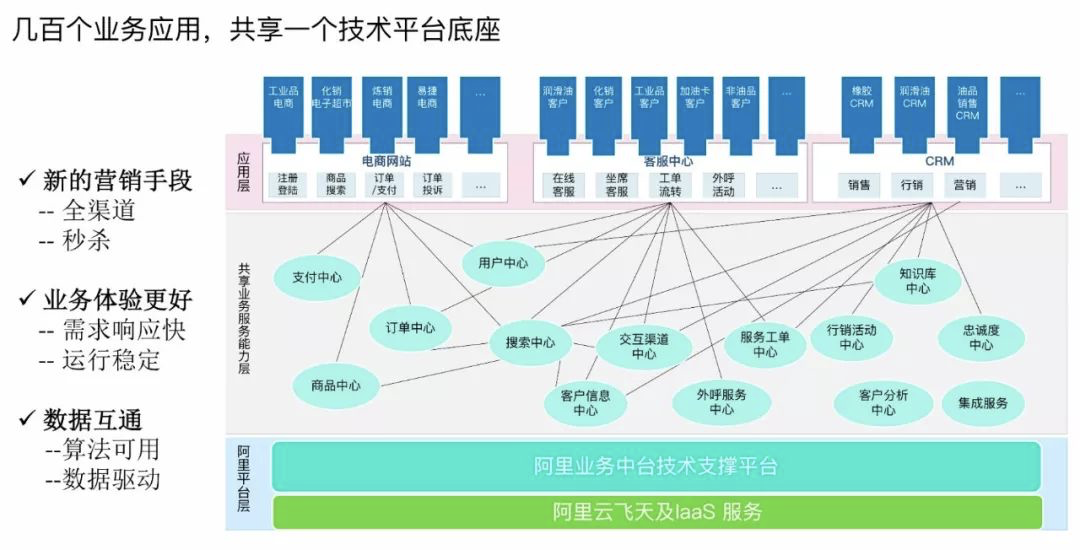
11、有没有合适的企业级的分布式知识图谱技术架构?
横向涉猎不多,答错勿怪。
titian就是分布式的,因为它是基于hbase的。
Neo4j 好像就不支持,不像hbase这么简单就可以进行扩展。
12、知识图谱存储会不会引起数据膨胀?
图数据库本身不会,但是知识图谱这个系统会,一份数据至少存在于hive加工区和hbase查询区,还有少量的elasticsearch索引区。
13、关于实体、属性、关系的识别和存储?
大多数情况下实体关系属性都是比较明确的,因为知识图谱的建模是与现实世界相符的。
比如银行来说客户就是实体,姓名,身 份 证 号码,手机号都是属性。
关系相对稍微复杂一点,不过常见的关系也都比较明确,比如客户经理和贷款户,机构和对公客户,合同和借款人等等。
银行这边的实体基本上都是自然人、账号,机构,合同、押品等,关系就是实体之间的关系,比如账号和自然人的归属关系。
实体、关系和属性都是存在titan里的,交易明细存在hbase里。
14、脏数据的处理机制是什么?
知识图谱作为下游系统其实没有好的办法处理脏数据,基本上有两种策略:
第一:确定一个优先级,某个属性以哪个系统为准,当两个系统不一致时,不管对错永远以某个系统为准。
第二:前一种方法不适用的,就将这些数据打入“冷宫”,放到一张表里,定期拿出来,找原系统进行数据修正,这是一个比较漫长的过程。
不过好在,80%以上的数据是正常的,脏数据多数由于客户长期未发生业务,渠道无法强制客户更新数据。
15、如何解决外部数据源准确性?
我个人无法从根本上解决,因为我们只是数据的使用方,准确性是需要从产生的根源上解决的问题。
不过在使用的时候可以进行多数据源的交叉验证,来提高准确性,完全消除是难以实现的。
16、用知识图谱做传统的风控行业,局限性在哪里?利用大数据挖掘,除知识图谱外,还有哪些比较好的风控模型?
1.知识图谱是一种工具,是一种与关系型数据库相对的数据组织方式,有其擅长的领域,但不能手里拿着锤子,看哪里都是钉子。知识图谱也有不擅长的领域。
2.除大数据外,基于传统的关系型数据库开发一些机器学习或深度学习模型也可以做到风控。
原文链接:
https://mp.weixin.qq.com/s/kAxnYpW16fc-JvwhAA8onA